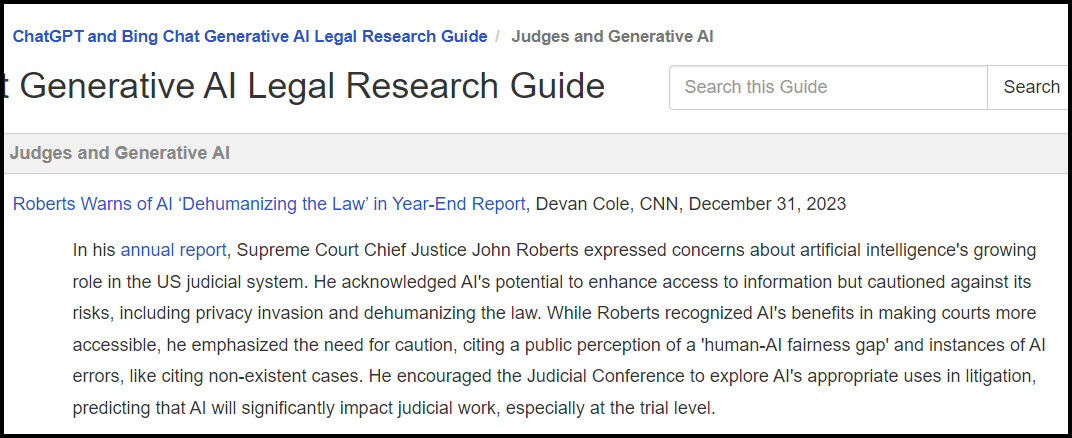
While taking a well-deserved break from the grind of writing memos and analyzing the news of the day, Claude (aka the illustrious author Claudia Trey) penned a 77-page extensively footnoted law review article that’s causing quite a stir on SSRN entitled “Bloodlines Over Merits: Exposing the Discriminatory Impact of Legacy Preferences in College Admissions.”
Hahaha, just kidding! It only has 11 downloads and at least 3 are from when I clicked on it while trying to determine which version of the article I uploaded. Though not setting the world on fire in the sense that the article is interesting or that anyone wants to read it, it showcases Claude’s abilities. Now, we all know that AI text generators can churn out an endless stream of words on just about any topic if you keep typing in the prompts. However, Claude can not only generate well-written text, but it can also provide footnotes to primary legal materials with minimal hallucination, setting it apart from other AI text generators such as ChatGPT-4. And, although Claude’s citations to other sources are generally not completely accurate, it is usually not too difficult to find the intended source or a similar one based on the information supplied.

Claude 3’s Writing Process
Inspired by new reports of AI-generated scientific papers flooding academic journals, I was curious to explore whether Claude could produce anything like a law review article. I randomly chose something I saw recently in the news, about how the criticism of legacy admissions at elite universities had increased in the post-Students for Fair Admissions anti-affirmative action decision era. Aware that Claude’s training data only extends up to August of 2023, and that its case law knowledge seems to clunk out in the middle of 2022, I attempted to enhance its understanding by uploading some recent law review articles discussing legacy admissions alongside the text of the Students for Fair Admissions decision. However, the combined size of these documents exceeded the upload limit, so I abandoned the attempt to include the case text.
Computer scientists and other commentators say all sorts of things about how to improve the performance of these large AI language models. Although I haven’t conducted a systematic comparison, my experience – whether through perception or imagination sparked by the power of suggestion – is that the following recommendations are actually helpful. I don’t know if they are helpful with Claude, since I just followed my usual prompting practices.
- Being polite and encouraging.
- Allowing ample time for the model to process information.
- Structuring inquiries in a sequential manner to enhance analysis and promote chain of thought reasoning.
- Supplying extensive, and sometimes seemingly excessive, background info and context.

I asked it to generate a table of contents, and then start generating the sections from the table of contents, and it was off to the races!
Roadblocks to the Process
It looked like Claude law review generation was going to be a quick process! It quickly generated all of section I. and was almost finished with II. when it hit a Claude 3 roadblock. Sadly, there is a usage limit. If your conversations are relatively short, around 200 English sentences, you can typically send at least 100 messages every 8 hours, often more depending on Claude’s current capacity. However, this limit is reached much quicker with longer conversations or when including large file attachments. Anthropic will notify you when you have 20 messages remaining, with the message limit resetting every 8 hours.

Although this was annoying, the real problem lies in Claude’s length limit. The largest amount of text Claude can handle, including uploaded files, is defined by its context window. Currently, the context window for Claude 3 spans over 200k+ tokens, which equates to approximately 350 pages of text. After this limit is reached, Claude 3’s performance begins to degrade, prompting the system to declare an end to the message with the announcement, “Your message is over the length limit.” Consequently, one must start anew in a new chat, with all previous information forgotten by the system. Therefore, for nearly each section, I had to re-upload the files, explain what I wanted, show it the table of contents it had generated, and ask it to generate the next section.
Claude 3 and Footnotes
It was quite a hassle to have to reintroduce it to the subject for the next seven sections from its table of contents. On the bright side, I was pretty pleased with the results of Claude’s efforts. From a series of relatively short prompts and some uploaded documents, it analyzed the legal issue and came up with arguments that made sense. It created a comprehensive table of contents, and then generated well-written text for each section and subsection of its outline. The text it produced contained numerous footnotes to primary and secondary sources, just like a typical law review article. According to a brief analyzer product, nearly all the cases and law review citations were non-hallucinated. Although none of the quotations or pinpoint citations I looked at were accurate, they were often fairly close. While most of the secondary source citations, apart from those referencing law review articles, were not entirely accurate, they were often sufficiently close that I could locate the intended source based on the partially hallucinated citator. If not, it didn’t take much time to locate something that seemed really similar. I endeavored to correct some of the citation information, but I only managed to get through about 10 in the version posted on SSRN before getting bored and abandoning the effort.

Claudia Trey Graces SSRN
Though I asked, sadly Claude couldn’t give me results in a Word document format so the footnotes would be where footnotes should be. So, for some inexplicable reason, I decided to insert them manually. This was a huge waste of time, but at a certain point, I felt the illogical pull of sunk cost silliness and finished them all. Inspired by having wasted so much time, I wasted even more by generating a table of contents for the article. I improved the author name from Claude to Claudia Trey and posted the 77-page masterwork on SSRN. While the article has sparked little interest, with only 11 downloads and 57 abstract views (some of which were my own attempts to determine which version I had uploaded), I am sure that if Claudia Trey has anything like human hubris, it will credit itself at least partially for the flurry of state legacy admission banning activity that has followed the paper’s publication.
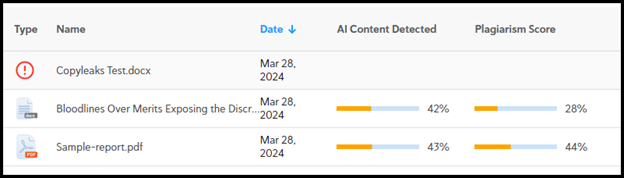
Obviously, it is not time to spam law reviews with Claudia Trey and friends’ generated articles, because according to Copyleaks, it didn’t do all that well in avoiding plagiarism (although plagiarism detection software massively over-detects it for legal articles due to citations and quotations) or evading detection as AI-generated.
What is to Come?
However, it is very early days for these AI text generators, so one wonders what is to come in the future for not only legal but all areas of academic writing.