Today’s guest post comes from Debbie Ginsberg, Faculty Services Manager at Harvard Law School Library.
I was supposed to write a blog post about the Harvard AI summit about six months ago. For various reasons (e.g., “didn’t get my act together”), that hasn’t happened. But one of the things that was brought up at the summit was who wasn’t at the table—who didn’t have access, whose data wasn’t included, and similar issues.
Since then, I’ve been thinking about the haves and have-nots of AI. There’s one group that I don’t think gets discussed enough. That’s the giant human workforce that AI needs to function.
Whenever I think of how AI is trained, I imagine a bunch of people somewhat like her (ok, there aren’t so many women and POC in real life, but I’m not going to tell ChatGPT to draw more white men):
And that they’ve been working on processes that look somewhat like this:
But that’s only part of the picture. Underlying all these processes are people like this:
The workers are generally paid piecemeal, which means they often earn very little per hour. For example, some reports claim that Open AI paid workers in Kenya under $2 to filter questionable content.
The working conditions are not optimal, especially when the workers are reviewing content. The workers generally do not receive sufficient training or time to do the work they are asked to do. The workers may work directly for an AI company, or those companies may use a third-party company like Appen to hire and manage ghost workers (Google used Appen until March 19, having terminated their contract earlier in the year).
That said, this work is an essential source of income for many around the world. The jobs are relatively flexible as to location and time, and the workers take pride in their output.
And considering how much profit is at stake, I’m thinking that maybe they should paid more than $2/hour.
Footnote:
Did I use AI to write this? Kind of? I used Google’s NotebookLM tool to review my sources and create notes. In addition to the sources above, check out:
I’ve been incredibly excited about the premium version of Claude 3 since its release on March 4, 2024, and for good reason. Now that my previous favorite chatty chatbot, ChatGPT-4, has gone off the rails, I was missing a competent chatbot… I signed up the second I heard on March 4th, and it has been a pleasure to use Claude 3 ever since. It actually understands my prompts and usually provides me with impressive answers. Anthropic, maker of the Claude chatty chatbot family, has been touting Claude’s accomplishments of supposedly beating its competitors on common chatbot benchmarks, and commentators on the Internet have been singing its praises. Just last week, I was so impressed by its ability to analyze information in news stories in uploaded files that I wrote a LinkedIn post also singing its praises!
Hesitation After Previous Struggles
Despite my high hopes for its legal research abilities after experimenting with it last week, I was hesitant to test Claude 3. I have a rule about intentionally irritating myself—if I’m not already irritated, I don’t go looking for irritation… Over the past several weeks, I’ve wasted countless hours trying to improve the legal research capabilities of ChatGPT-3.5, ChatGPT-4, Microsoft Copilot, and my legal research/memo writing GPTs through the magic of (IMHO) clever prompting and repetition. Sadly, I failed miserably and concluded that either ChatGPT-4 was suffering from some form of robotic dementia, or I am. The process was a frustrating waste, and I knew that Claude 3 doing a bad job of legal research too could send me over the edge….
Claude 3’s Wrote a Pretty Good Legal Memorandum!
Luckily for me, when I finally got up the nerve to test out the abilities of Claude 3, I found that the internet hype was not overstated. Somehow, Claude 3 has suddenly leapfrogged over its competitors in legal research/legal analysis/legal memo writing ability – it instantly did what would have taken a skilled researcher over an hour and produced a better legal memorandum which is probably better than that produced by many law students and even some lawyers. Check it out for yourself! Unless this link actually works for any Claude 3 subscribers out there, there doesn’t seem to be a way to actually link to a Claude 3 chat at this time. However, click here for the whole chat I cut and pasted into a Google Drive document, here for a very long screenshot image of the chat, or here for the final 1,446-word version of the memo as a Word document.
Comparing Claude 3 with Other Systems
Back to my story… The students’ research assignment for the last class was to think of some prompts and compare the results of ChatGPT-3.5, Lexis+ AI, Microsoft Copilot, and a system of their choice. Claude 3 did not exist at the time, but I told them not to try the free Claude product because I had canceled my $20.00 subscription to the Claude 2 product in January 2024 due to its inability to provide useful answers – all it would say was that it was unethical to answer every question and tell me to do it myself. When creating an answer sheet before class tomorrow which compares the same set of prompts on different systems, I decided to omit Lexis+ AI (because I find it useless) and to include my new fav Claude 3 in my comparison spreadsheet. Check it out to compare for yourself!
For the research part of the assignment, all systems were given a fact pattern and asked to “Please analyze this issue and then list and summarize the relevant Texas statutes and cases on the issue.” While the other systems either made up cases or produced just two or three actual real and correctly cited cases on the research topic, Claude 3 stood out by generating 7 real, relevant cases with correct citations in response to the legal research question. (And, it cited to 12 cases in the final version of its memo.)
It did a really good job of analysis too!
Generating a Legal Memorandum
Writing a memo was not part of the class assignment because the ChatGPT family was refusing the last few weeks,* and Bing Copilot had to be tricked into writing one as part of a short story, but after seeing Claude 3’s research/analysis results, I decided to just see what happened. I have many elaborate prompts for ChatGPT-4 and my legal memorandum GPTs, but I recalled reading that Claude 3 worked well with zero-shot prompting and didn’t require much explanation to produce good results. So, I decided to keep my prompt simple – “Please generate a draft of a 1500 word memorandum of law about whether Snurpa is likely to prevail in a suit for false imprisonment against Mallatexaspurses. Please put your citations in Bluebook citation format.”
From my experience last week with Claude 3 (and prior experience with Claude 2 which would actually answer questions), I knew the system wouldn’t give me as long an answer as requested. The first attempt yielded a pretty high-quality 735-word draft memo that cited all real cases with the correct citations*** and applied the law to the facts in a well-organized Discussion section. I asked it to expand the memo two more times, and it finally produced a 1,446-word document. Here is part of the Discussion section…
Implications for My Teaching
I’m thrilled about this great leap forward in legal research and writing, and I’m excited to share this information with my legal research students tomorrow in our last meeting of the semester. This is particularly important because I did such a poor job illustrating how these systems could be helpful for legal research when all the compared systems were producing inadequate results.
However, with my administrative law legal research class starting tomorrow, I’m not sure how this will affect my teaching going forward. I had my video presentation ready for tomorrow, but now I have to change it! Moreover, if Claude 3 can suddenly do such a good job analyzing a fact pattern, performing legal research, and applying the law to the facts, how does this affect what I am going to teach them this semester?
*Weirdly, the ChatGPT family, perhaps spurred on by competition from Claude 3, agreed to attempt to generate memos today, which it hasn’t done in weeks…
Note: Claude 2 could at one time produce an okay draft of a legal memo if you uploaded the cases for it, that was months ago (Claude 2 link if it works for premium subscribers and Google Drive link of cut and pasted chat). Requests in January resulted in lectures about ethics which resulted in the above-mentioned cancellation.
Is it just me, or has ChatGPT-4 taken a nosedive when it comes to legal research and writing? There has been a noticeable decline in its ability to locate primary authority on a topic, analyze a fact pattern, and apply law to facts to answer legal questions. Recently, instructions slide through its digital grasp like water through a sieve, and its memory? I would compare it to a goldfish, but I don’t want to insult them. And before you think it’s just me, it’s not just me, the internet agrees!
ChatGPT’s Sad Decline
One of the hottest topics in the OpenAI community, in the aptly named GPT-4 is getting worse and worse every single update thread, is the perceived decline in the quality and performance of the GPT-4 model, especially after the November 2023 update. Many users have reported that the model is deteriorating with each update, producing nonsensical, irrelevant, or incomplete outputs, forgetting the context, and ignoring instructions. Some users have even reverted to previous versions of the model or cancelled their subscriptions. Here are some specific quotations from recent comments about the memory problem:
December 2023 – “I don’t know what on Earth is wrong with GPT 4 lately. It feels like I’m talking to early 3.5! It’s incapable of following basic instructions and forgets the format it’s working on after just a few posts.”
December 2023 – “It ignores my instructions, in the same message. I can’t be more specific with what I need. I’m needing to repeat how I’d like it to respond every single message because it forgets, and ignores.”
December 2023 – “ChatGPT-4 seems to have trouble following instructions and prompts consistently. It often goes off-topic or fails to understand the context of the conversation, making it challenging to get the desired responses.”
January 2024 – “…its memory is bad, it tells you search the net, bing search still sucks, why would teams use this product over a ChatGPT Pre Nov 2023.”
February 2024 – “It has been AWFUL this year…by the time you get it to do what you want format wise it literally forgets all the important context LOL — I hope they fix this ASAP…”
February 2024 – “Chatgpt was awesome last year, but now it’s absolutely dumb, it forgets your conversation after three messages.”
OpenAI has acknowledged the issue and released an updated GPT-4 Turbo preview model, which is supposed to reduce the cases of “laziness” and complete tasks more thoroughly. However, the feedback from users is still mixed, and some are skeptical about the effectiveness of the fix.
An Example of Confusion and Forgetfulness from Yesterday
Here is one of many examples of my experiences which provide an illustrative example of the short-term memory and instruction following issues that other ChatGPT-4 users have reported. Yesterday, I asked it to find some Texas cases about the shopkeeper’s defense to false imprisonment. Initially, ChatGPT-4 retrieved and summarized some relatively decent cases. Well, to be honest, it retrieved 2 relevant cases, with one of the two dating back to 1947… But anyway, the decline in case law research ability is a subject for another blog post.
Anyway, in an attempt to get ChatGPT-4 to find the cases on the internet so it could properly summarize them, I provided some instructions and specified the format I wanted for my answers. Click here for the transcript (only available to ChatGPT-4 subscribers).
Confusion ran amok! ChatGPT-4 apparently understood the instructions (which was a positive sign) and presented three cases in the correct format. However, they weren’t the three cases ChatGPT had listed; instead, they were entirely irrelevant to the topic—just random criminal cases.
It remembered… and then forgot. When reminded that I wanted it to work with the first case listed and provided the citation, it apologized for the confusion. It then proceeded to give the correct citation, URL, and a detailed summary, but unfortunately in the wrong format!
Eventually, in a subsequent chat, I successfully got it to take a case it found, locate the text of the case on the internet, and then provide the information in a specified format. However, it could only do it once before completely forgetting about the specified format. I had to keep cutting and pasting the instructions for each subsequent case.
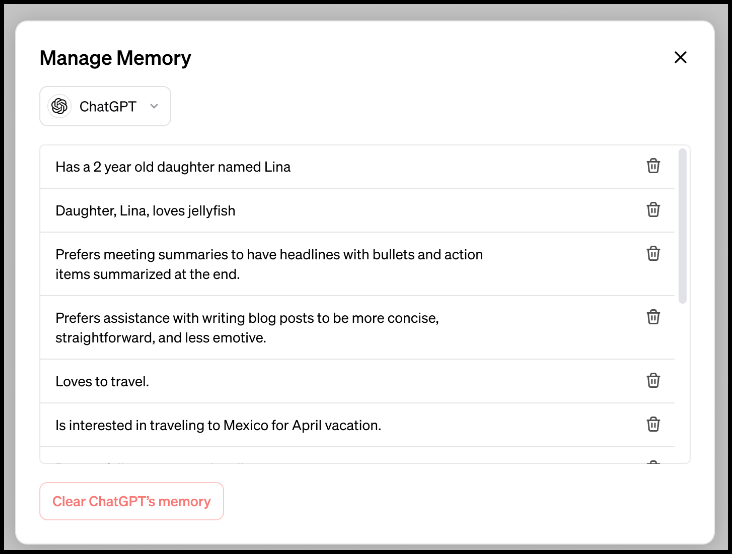
Well, the news is not all bad! While we are on the topic of memory, OpenAI has introduced a new feature for ChatGPT – the ability to remember stuff over time. ChatGPT’s memory feature is being rolled out to a small portion of free and Plus users, with broader availability planned soon. According to OpenAI, this enhancement allows ChatGPT to remember information from past interactions, resulting in more personalized and coherent conversations. During conversations, ChatGPT automatically picks up on details it deems relevant to remember. Users can also explicitly instruct ChatGPT to remember specific information, such as meeting note preferences or personal details. Over time, ChatGPT’s memory improves as users engage with it more frequently. This memory feature could be useful for users who want consistent responses, such as replying to emails in a specific format.
The memory feature can be turned off entirely if desired, giving users control over their experience. Deleting a chat doesn’t erase ChatGPT’s memories; users must delete specific memories individually…which seems a bit strange – see below. For conversations without memory, users can use temporary chat, which won’t appear in history, won’t use memory, and won’t train the AI model.
The Future?
As we await improvements to our once-loved ChatGPT-4, our options remain limited, pushing us to consider alternative avenues. Sadly, I’ve encountered recent similar shortcomings with the once-useful for legal research and writing Claude 2. In my pursuit of alternatives, platforms like Gemini, Perplexity, and Hugging Face have proven less than ideal for research and writing tasks. However, amidst these challenges, Microsoft Copilot has shown promise. While not without its flaws, it recently demonstrated adequate performance in legal research and even took a passable stab at a draft of a memo. Given OpenAI’s recent advancements in the form of Sora, the near-magical text-to-video generator that is causing such hysteria in Hollywood, there’s reason to hope that they can pull ChatGPT back from the brink.
In his 1908 essay, “Mechanical Jurisprudence,” the eminent legal scholar Roscoe Pound warns of the dangers of what he calls “scientific law,” namely a “petrification” that “tends to cut off individual initiative in the future, to stifle independent consideration of new problems and of new phases of old problems, and so to impose the ideas of one generation upon the other.” Today, this century-old critique of legal formalism could be used to describe the pitfalls of so-called “AI-driven” legal research and law practice technologies.
Pound’s early work served as the foundation for legal realism, an intellectual movement that radically transformed American law by exposing the human element in judicial decision-making and introducing the indeterminacy thesis—the idea that “laws (broadly defined to include cases, regulations, statutes, constitutional provisions, and other legal materials) do not determine legal outcomes.” Unfortunately, the insights of the legal realists are lost on the founders of today’s legal tech startups and their promoters, even those within the legal academy. As Upton Sinclair once wrote, “It is difficult to get a man to understand something when his salary depends on his not understanding it.”
Yet foundational questions abound. Is law determinate? What systemic biases and hidden assumptions are embedded in the corpus of Anglo-American law? What are the implications of turning the corpus of Anglo-American law into a dataset and automating it? Will AI inhibit the legal creativity exemplified by lawyers like Thurgood Marshall and Ruth Bader Ginsburg? What will all of this mean for the future of law reform? While we can hardly expect vendors to take time to reflect upon these questions, law librarians, in their roles as legal research professors and legal information scholars, must.
Hallucinations in generative AI are not a new topic. If you watch the news at all (or read the front page of the New York Times), you’ve heard of the two New York attorneys who used ChatGPT to create fake cases entire cases and then submitted them to the court.
After that case, which resulted in a media frenzy and (somewhat mild) court sanctions, many attorneys are wary of using generative AI for legal research. But vendors are working to limit hallucinations and increase trust. And some legal tasks are less affected by hallucinations. Understanding how and why hallucinations occur can help us evaluate new products and identify lower-risk uses.
* A brief aside on the term “hallucinations”. Some commentators have cautioned against this term, arguing that it lets corporations shift the blame to the AI for the choices they’ve made about their models. They argue that AI isn’t hallucinating, it’s making things up, or producing errors or mistakes, or even just bullshitting. I’ll use the word hallucinations here, as the term is common in computer science, but I recognize it does minimize the issue.
With that all in mind, let’s dive in.
What are hallucinations and why do they happen?
Hallucinations are outputs from LLMs and generative AI that look coherent but are wrong or absurd. They may come from errors or gaps in the training data (that “garbage in, garbage out” saw). For example, a model may be trained on internet sources like Quora posts or Reddit, which may have inaccuracies. (Check out this Washington Post article to see how both of those sources were used to develop Google’s C4, which was used to train many models including GPT-3.5).
But just as importantly, hallucinations may arise from the nature of the task we are giving to the model. The objective during text generation is to produce human-like, coherent and contextually relevant responses, but the model does not check responses for truth. And simply asking the model if its responses are accurate is not sufficient.
In the legal research context, we see a few different types of hallucinations:
Citation hallucinations. Generative AI citations to authority typically look extremely convincing, following the citation conventions fairly well, and sometimes even including papers from known authors. This presents a challenge for legal readers, as they might evaluate the usefulness of a citation based on its appearance—assuming that a correctly formatted citation from a journal or court they recognize is likely to be valid.
Hallucinations about the facts of cases. Even when a citation is correct, the model might not correctly describe the facts of the case or its legal principles. Sometimes, it may present a plausible but incorrect summary or mix up details from different cases. This type of hallucination poses a risk to legal professionals who rely on accurate case summaries for their research and arguments.
Hallucinations about legal doctrine. In some instances, the model may generate inaccurate or outdated legal doctrines or principles, which can mislead users who rely on the AI-generated content for legal research.
In my own experience, I’ve found that hallucinations are most likely to occur when the model does not have much in its training data that is useful to answer the question. Rather than telling me the training data cannot help answer the question (similar to a “0 results” message in Westlaw or Lexis), the generative AI chatbots seem to just do their best to produce a plausible-looking answer.
This does seem to be what happened to the attorneys in Mata v. Avianca. They did not ask the model to answer a legal question, but instead asked it to craft an argument for their side of the issue. Rather than saying that argument would be unsupported, the model dutifully crafted an argument, and used fictional law since no real law existed.
How are vendors and law firms addressing hallucinations?
Although vendors and firms are often close-lipped about how they have built their products, we can observe a few techniques that they are likely using to limit hallucinations and increase accuracy.
First, most vendors and firms appear to be using some form of retrieval-augmented generation (RAG). RAG combines two processes: information retrieval and text generation. The model takes the user’s question and passes it (perhaps with some modification) to a database. The database results are fed to the model, and the model identifies relevant passages or snippets from the results, and again sends them back into the model as “context” along with the user’s question.
This reduces hallucinations, because the model receives instructions to limit its responses to the source documents it has received from the database. Several vendors and firms have said they are using retrieval-augmented generation to ground their models in real legal sources, including Gunderson, Westlaw, and Casetext.
To enhance the precision of the retrieved documents, some products may also use vector embedding. Vector embedding is a way of representing words, phrases, or even entire documents as numerical vectors. The beauty of this method lies in its ability to identify semantic similarities. So, a query about “contract termination due to breach” might yield results related to “agreement dissolution because of violations”, thanks to the semantic nuances captured in the embeddings. Using vector embedding along with RAG can provide relevant results, while reducing hallucinations.
Another approach vendors can take is to develop specialized models trained on narrower, domain-specific datasets. This can help improve the accuracy and relevance of the AI-generated content, as the models would be better equipped to handle specific legal queries and issues. Focusing on narrower domains can also enable models to develop a deeper understanding of the relevant legal concepts and terminology. This does not appear to be what law firms or vendors are doing at this point, based on the way they are talking about their products, but there are law-specific data pools becoming available so we may see this soon.
Finally, vendors may fine-tune their models by providing human feedback on responses, either in-house or through user feedback. By providing users with the ability to flag and report hallucinations, vendors can collect valuable information to refine and retrain their models. This constant feedback mechanism can help the AI learn from its mistakes and improve over time, ultimately reducing the occurrence of hallucinations.
So, hallucinations are fixed?
Even though vendors and firms are addressing hallucinations with technical solutions, it does not necessarily mean that the problem is solved. Rather, it may be that our our quality control methods will shift.
For example, instead of wasting time checking each citation to see if it exists, we can be fairly sure that the cases produced by legal research generative AI tools do exist, since they are found in the vendor’s existing database of case law. We can also be fairly sure that the language they quote from the case is accurate. What may be less certain is whether the quoted portions are the best portions of the case and whether the summary reflects all relevant information from the case. This will require some assessment of the various vendor tools.
We will also need to pay close attention to the databases results that are fed into retrieval augmented generation. If those results don’t reflect the full universe of relevant cases, or contain material that is not authoritative, then the answer generated from those results will be incomplete. Think of running an initial Westlaw search, getting 20 pretty good results, and then basing your answer only on those 20 results. For some questions (and searches), that would be sufficient, but for more complicated issues, you may need to run multiple searches, with different strategies, to get what you want.
To be fair, the products do appear to be running multiple searches. When I attended the rash of AI presentations at AALL over the summer, I asked Jeff Pfeiffer of Lexis how he could be sure that the model had all relevant results, and he mentioned that the model sends many, many searches to the database not just one. Which does give some comfort, but leads me to the next point of quality control.
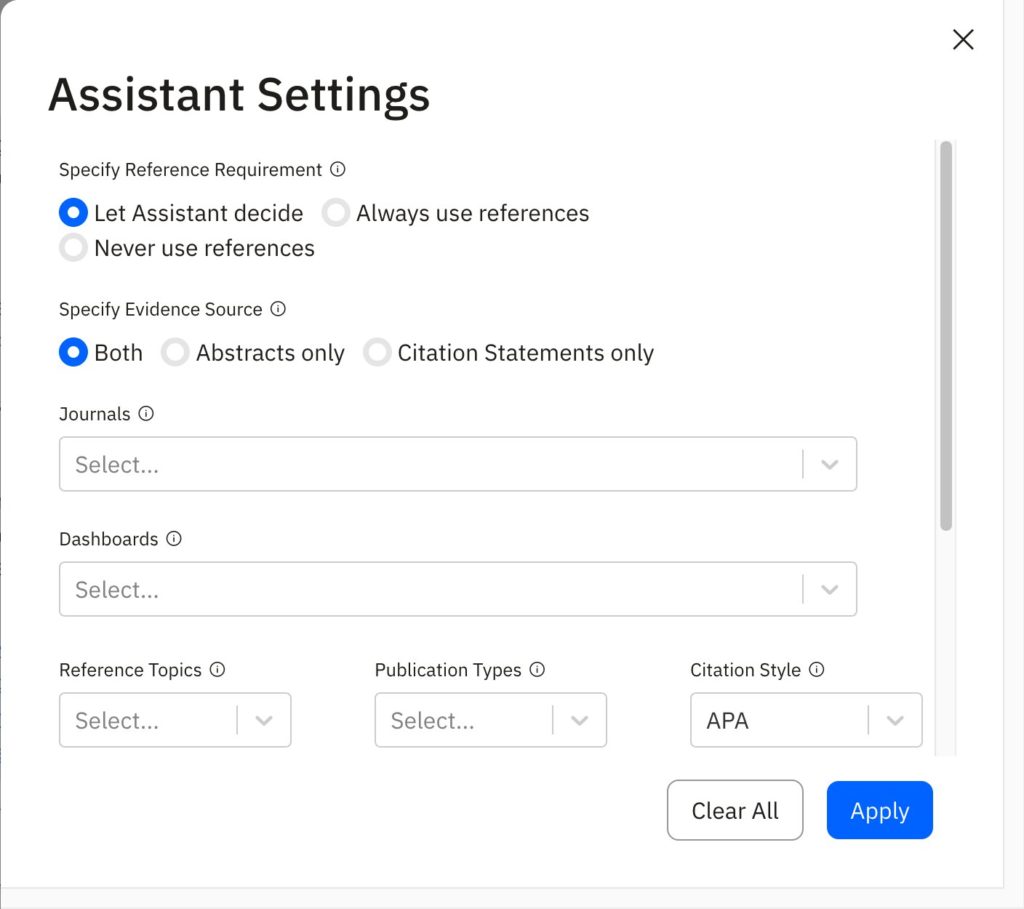
We will want to have some insight into the searches that are being run, so that we can verify that they are asking the right questions. From the demos I’ve seen of CoCounsel and Lexis+ AI, this is not currently a feature. But it could be. For example, the AI assistant from scite (an academic research tool) sends searches to academic research databases and (seemingly using RAG and other techniques to analyze the search results) produces an answer. They also give a mini-research trail, showing the searches that are being run against the database and then allowing you to adjust if that’s not what you wanted.
scite AI Assistant Sample ResultssCcite AI Assistant Settings
Are there uses for generative AI where the risks presented by hallucinations are lessened?
The other good news is that there are plenty of tasks we can give generative AI for which hallucinations are less of an issue. For example, CoCounsel has several other “skills” that do not depend upon accuracy of legal research, but are instead ways of working with and transforming documents that you provide to the tool.
Similarly, even working with a generally applicable tool such as ChatGPT, there are many applications that do not require precise legal accuracy. There are two rules of thumb I like to keep in mind when thinking about tasks to give to ChatGPT: (1) could this information be found via Google? and (2) is a somewhat average answer ok? (As one commentator memorably put it “Because [LLMs] work by predicting the most statistically likely word in a sentence, they churn out average content by design.”)
For most legal research questions, we could not find an answer using Google, which is why we turn to Westlaw or Lexis. But if we just need someone to explain the elements of breach of contract to us, or come up with hypotheticals to test our knowledge, it’s quite likely that content like that has appeared on the internet, and ChatGPT can generate something helpful.
Similarly, for many legal research questions, an average answer would not work, and we may need to be more in-depth in our answers. But for other tasks, an average answer is just fine. For example, if you need help coming up with an outline or an initial draft for a paper, there are likely hundreds of samples in the data set, and there is no need to reinvent the wheel, so ChatGPT or a similar product would work well.
What’s next?
In the coming months, as legal research generative AI products become increasingly available, librarians will need to adapt to develop methods for assessing accuracy. Currently, there appear to be no benchmarks to compare hallucinations across platforms. Knowing librarians, that won’t be the case for long, at least with respect to legal research.
Further reading
If you want to learn more about how retrieval augmented generation and vector embedding work within the context of generative AI, check out some of these sources: