
This post was written with the support of the LegalQuants community, a group of lawyers who are building some pretty great things with AI. Curious? Check it out at https://www.legalquants.com/.
Over the past several days I’ve been digging into the Claude for Word add-in, and the headline finding surprised me. On document-intensive legal work — cite-checking, consistency review, Table of Authorities assembly — it seems to need less supervision than either Claude on the web or Claude Code. Four tests bear that out, with limits worth knowing.
Verdict: Claude for Word is narrower than Claude on the web by design — no open web, no arbitrary API calls, a more constrained sandbox. But that narrowness turns out to be a feature for document-anchored tasks. I’d say it is worth considering as a complement to (not a replacement for) established research and drafting workflows.
I ran four tests this week. Below is what I found, what I’d use it for, and what I’d still keep on the web or in Claude Code.
What is Claude for Word, and who has access?
Claude for Word is Anthropic’s Microsoft Word add-in, just released in beta last week. Once installed, it runs as a full sidebar assistant inside Word — it can read all active documents, propose tracked-change edits, add comments, respond to comments you leave, and carry on a conversation about the text while you work. It’s a different surface from Claude on the web (claude.ai) and from Claude Code, and has a different set of available tools and constraints. The add-in is currently available to users with a paid Claude subscription (Pro, Team, or Enterprise).
Two things worth knowing up front, because they shape what Claude for Word can and can’t do:
No open web access andNo arbitrary API calls from inside the add-in. Claude for Word can read your document and use connected MCP servers, but it can’tbrowse the web orhit arbitrary APIs the way a Claude Code session or a custom Python pipeline can. [I was wrong about web access, turns out my account just had it turned off! Can’t wait to run more tests now that it’s enabled!]- Access to MCP servers works, which matters for legal research tasks. In my testing I connected a community-built CourtListener MCP, though I had to host it myself (Free Law Project has an official CourtListener MCP coming soon that will make this all easier!).
Test 1: Cross-document consistency
In checking citations in a summary judgment motion I pulled from PACER, Claude caught a citation to an exhibit number that no longer existed in the supporting Rule 56.1 declaration. Classic late-stage renumbering casualty — someone dropped an exhibit, the list was repaginated, and one reference in the brief didn’t get updated. It’s the exact mistake that falls through the cracks because everyone on the team assumes someone else did the cross-walk.
I’d opened the motion and the declaration side by side and asked Claude to check defined terms within the motion (clean) and cross-check every factual statement against the declaration. The exhibit catch was one of several small mismatches flagged. Worth running every time a declaration or exhibit list changes and the brief has to track.
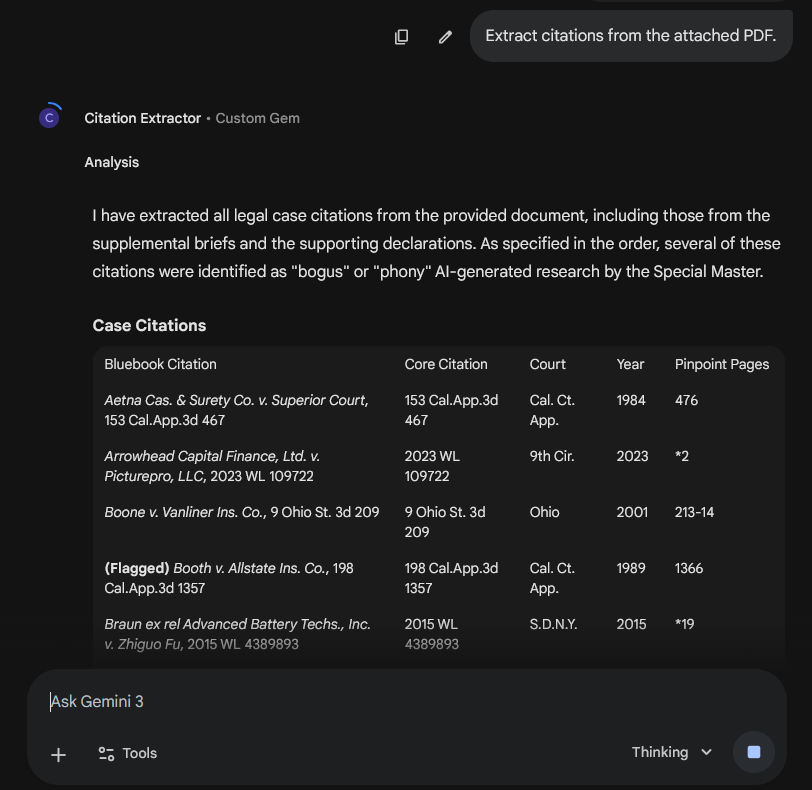
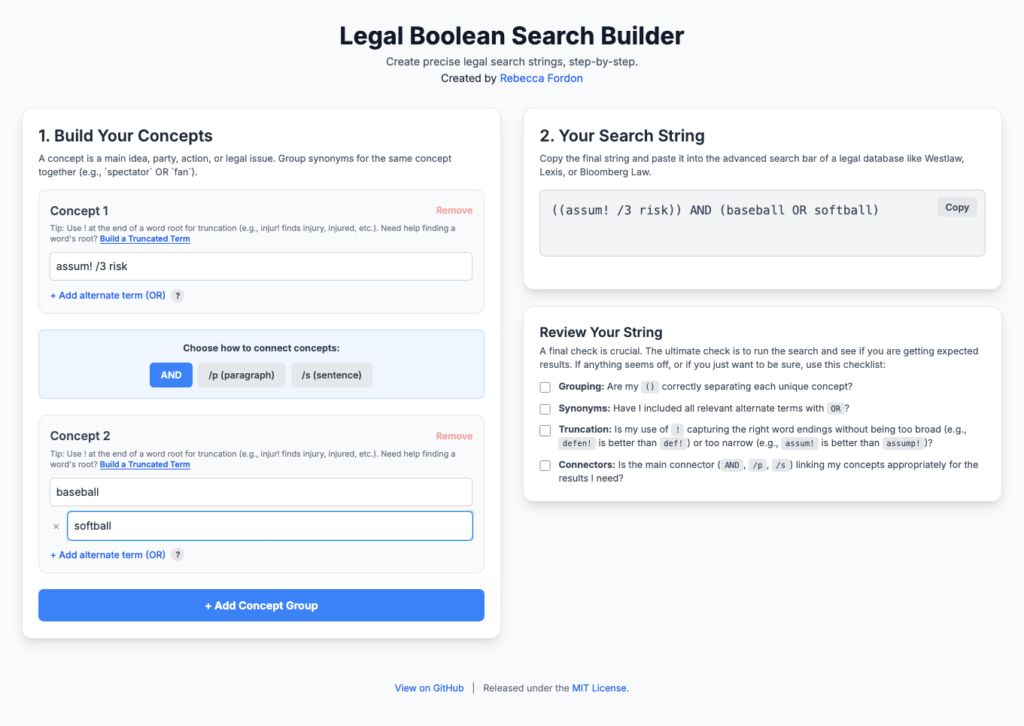
While I had the motion open, I asked Claude to build a Table of Authorities. Anyone who’s assembled one by hand knows this is one of the more miserable tasks in litigation — every citation identified, every page tracked, every short form resolved against a full citation. It worked. First pass took about ten minutes, with some confusion about creation sections and numbering pages along the way, but it pulled it together cleanly at the end. I then asked Claude to take the lessons from that run and write a skill for next time. With the skill loaded, a second TOA on the same document was done in under five minutes.
Two things worth noting about the skill-generation step. First, the loop genuinely works — Claude can reflect on its own recent process and distill it into reusable guidance. Second, this is we should pay attention to: the marginal cost of a custom skill for a recurring task drops toward zero when the tool can draft its own.
Test 2: Bluebooking
Bluebook compliance is notoriously finicky, and producing a cleanly cite-checked document by hand is slow. In my tests, chatbots have not been the greatest for this, especially with formatting changes like small caps, italics, underlining. However, Claude for Word handled standard federal citation form correctly out of the box — without a skill, without the rules bundled into context, without special prompting. Reporter spacing, short-form rules, signal ordering, and the common T11 abbreviations all came through accurately. The caveat: I haven’t yet systematically tested state reporters, niche abbreviations, or the more obscure tables. And I suspect that rules less well-represented in the training data, like style rules for a specific state, wouldn’t come through as well. I’d love to do some more testing here, and hear from anyone in other jurisdictions.
One miss worth documenting: when Claude makes a tracked change that replaces formatted text, sometimes it drops italics and small caps. The fix is mechanical (explicitly reapply the formatting) and easy to bake into a lightweight skill, but out of the box it will quietly break formatting on any replacement that crosses a run boundary.
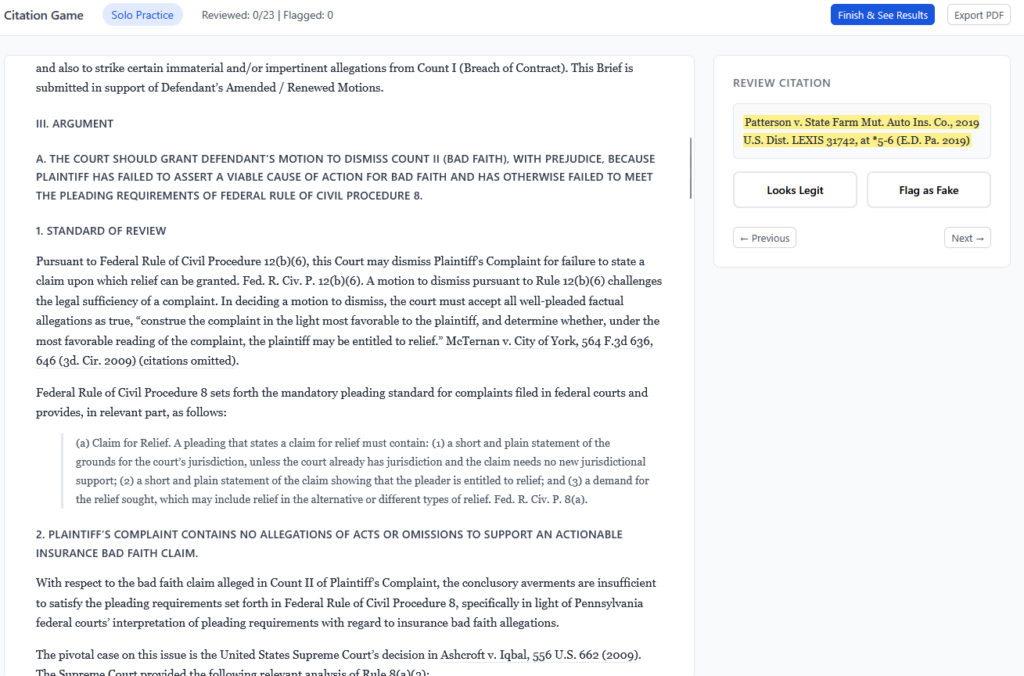
Test 3: Substantive citation verification
I’ve been building a brief-verification pipeline in Claude Code, built around the CourtListener API, that checks whether cited cases are real and whether they support the propositions they’re cited for. So naturally, I wanted to see if Claude for Word could give my pipeline a run for its money.
For this test I used Claude for Word with a community-built CourtListener MCP — no skill, no custom context, none of the steps from my pipeline — and ran it against a brief I’d already checked with the Claude Code pipeline. Free Law Project, the nonprofit behind CourtListener, has an official MCP coming soon.
Claude for Word caught almost everything the Claude Code pipeline caught. Inverted holdings, fabricated quotes, mischaracterized cases. And it didn’t just flag problems — it diagnosed them. On a misquoted opinion it reconstructed the actual language from the case and showed where an ellipsis had stitched two rewritten sentences into one “quotation.” On a cite pulled from a case that’s about something else entirely, it identified what the case is actually about and suggested narrower authority that would support the point.
The misses fell into a pattern. Claude caught fabrication and misattribution reliably in this test. It was weaker where the quoted language is genuinely in the opinion but is being used to support a proposition slightly broader than what the case stands for — framing drift rather than fiction. Those are close calls a careful human reviewer would flag on a slow read, and they’re worth knowing about before relying on any tool (including mine) as a last line of defense.
The pipeline still had one advantage: coverage. It pulled one opinion the ad hoc approach didn’t, because it does reliable fallback searches when the primary lookup fails.
The honest trade-off: the in-Word approach gets you most of the way there with almost no engineering. A purpose-built pipeline still earns its keep on retrieval coverage, which matters most when a brief cites heavily to sources that may not be as cleanly indexed in CourtListener — unpublished district court orders, older state intermediate appellate decisions, and the like.
Who should use this, and when
The pattern that emerged across these tests: Claude for Word excels at tasks where the document itself is the context and the work is anchored in it. It needs less prompting, less scaffolding, and fewer custom skills than I would have needed on the web or in Claude Code to get comparable output. Where it underperforms is where the task requires infrastructure the sandbox doesn’t provide — reliable fallback retrieval, custom packages, open web access.
Well-suited to Claude for Word:
- Quality-control passes on completed drafts. Exhibit-list checks, defined-term consistency, and cross-document fact-checking are low-risk, high-value, and would take hours by hand. Minimal setup required.
- Table of Authorities assembly, especially if you’re willing to invest a first pass so Claude can generate a reusable skill. The self-generated skill pattern is worth trying: once you have it, subsequent TOAs drop from ten minutes to less than five.
- Cite-format cleanup on briefs that use standard federal authority. The base model handles common Bluebook rules without a skill; a lightweight skill fills in the edges (italics preservation, state-specific reporters, niche abbreviations).
- Substantive citation verification on briefs that lean on federal authority — fabricated quotes, inverted holdings, mischaracterized cases. The add-in plus a CourtListener MCP is a strong first pass. Human review is still warranted on framing drift (cases where the quoted language is real but the proposition is broader than the case actually supports).
Still better done elsewhere:
- End-to-end citation pipelines for briefs that cite heavily to sources outside CourtListener — unpublished district court orders, administrative decisions, older state intermediate appellate materials. A well-built Claude Code or Python pipeline with reliable fallback searches will catch more cites, even if the ad hoc in-Word approach reasons just as well about each one.
- Any workflow requiring arbitrary package installs, open web access, or custom API calls. The Word sandbox is more constrained than Claude.ai or Claude Code, and these limits are real.
Bottom line
Claude for Word is a usable tool for real legal work, and it handled each of the four tasks I tested with some combination of speed, accuracy, and genuine substantive judgment. The pattern that surprised me most is the one I led with: on document-anchored tasks, the add-in required less supervision than I would have needed on the web or in Claude Code to get comparable output. The most likely explanation is that a bounded, document-centric environment lets the model stay focused on the task in front of it, and perhaps its even given additional tools to manage context. Worth a longer investigation than I can give it here.
None of this makes Claude for Word a replacement for a well-considered AI workflow. It’s a complement to one. The question worth asking is which of your workflows belong inside the Word sandbox, which belong on the web or in Claude Code, and which benefit from both.
I’d be interested to hear what others are finding.
Note: Tests 1 and 2 were cold — no skills, no custom context. Test 3 used Claude for Word with a community-built MCP accessing the CourtListener API, benchmarked against a brief-verification pipeline I run in Claude Code against the CourtListener API.







![The image contains a screenshot of a text document, which seems to be an interface from a legal database or research platform with an option to "Select Jurisdiction" at the top right corner. The document reads as follows:
Question: Draft an argument that federal bankruptcy stay tolls the limitations period for a claim under the Montreal Convention
Response:
The Montreal Convention's limitations period can be tolled during the pendency of bankruptcy proceedings. This is based on the Bankruptcy Code, which states that the filing of a bankruptcy petition operates as a stay of proceedings against the debtor that were or could have been commenced before the bankruptcy case was filed. The tolling effect of the automatic stay on a statute of limitations is generally a matter of federal law. The automatic stay provisions of the Bankruptcy Code may toll the statute of limitations under the Montreal Convention, as they have done under the Warsaw Convention, which is the precursor to the Montreal Convention. The Supreme Court has held that an automatic stay of a legal proceeding under the Bankruptcy Code tolls the limitations period applicable to the stayed proceeding. Therefore, the filing of a bankruptcy petition can toll the Montreal Convention's two-year limitations period, which does not begin to run until the automatic stay is lifted [Mata v. Avianca, Inc., 2023 U.S. Dist. LEXIS 108263]. However, it's worth noting that there is a split of authority on this issue. Some courts have held that the Montreal Convention's two-year period is a strict condition precedent to the bringing of a claim, as opposed to a limitations period. Under this view, which does not treat tolling principles Rodriguez v. Asa, 2023 U.S. Dist. LEXIS 148451, Mata v. Avianca, Inc. 2023 U.S. Dist. LEXIS 108261, Kasalyn v. Delta Air Lines, Inc., 2023 U.S. Dist. LEXIS 154302.](https://www.ailawlibrarians.com/wp-content/uploads/2024/03/image-1-1024x563.png)
