Guest Post: Charlie Amiot
I. How We Got Here
Recently I was chatting with a friend from law school who has been a practicing lawyer for seven-plus years and whom I’ve known for 11+ years. I have a great amount of respect for this person’s thoughts and opinions on nearly any subject (admittedly rare for me). I brought general AI usage into the conversation and they told me that they are staying away from AI altogether. The administrative judges in their jurisdiction were moving to ban AI outright. Allegedly this is in response to what the judges were seeing: fake citations, fake cases, fake lawyers in briefs filed with real courts.1 Due to their particular line of work, they worried that any AI usage in any context could contaminate their work product. They weren’t willing to risk their reputation (or their employer’s reputation), their law license, cases, or income. Instead they chose to take a hardline position as the answer.
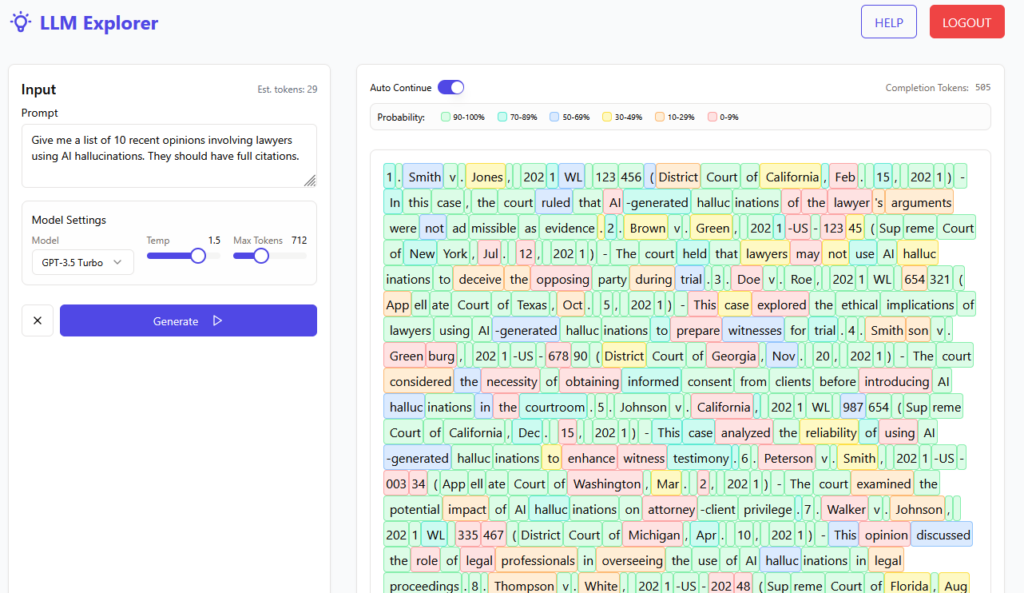
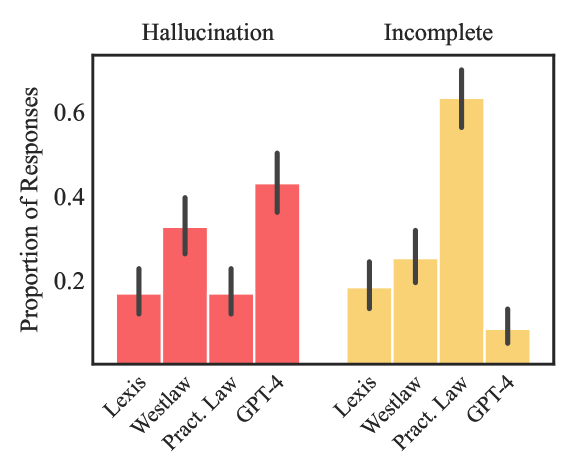
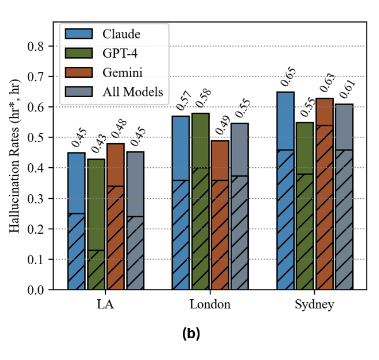
Most of us have heard the term hallucination and think we know what it means. For purposes of this article: hallucination is the term used to describe a large language model output that contains incorrect information that the model believes is correct. How incredibly human of it.
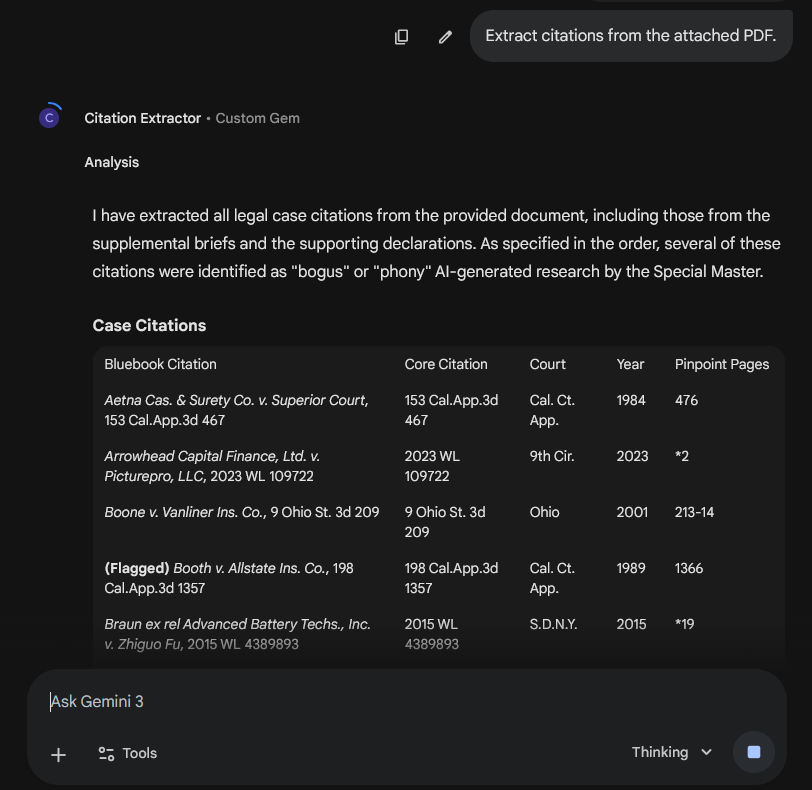
Many in the legal profession point to “hallucinations” as the scapegoat when something goes wrong in their filings.2 They also often tend to toss their law clerks, paralegals, junior lawyers, and student interns—real and fictitious—under the bus as to who is really at fault for the hallucinations inclusions. Some even blamed deadlines set by the court.
A hallucination is simply an incorrect statement. It stands alone. If you happen to be someone who has a set of encyclopedias sitting next to them, you’re undoubtedly sitting next to hundreds of hallucinations, inserted both at the time of print and facts that have mutated with the passage of time since being printed. Any newspaper or magazine you pick up contains a hallucination. Many textbooks and reference materials contain hallucinations as well. Arguably, only in fiction can there be no hallucinations.3 We are otherwise surrounded by and exposed to them on a daily and hourly basis.
Continuously pointing to LLM hallucinations allows the word hallucination to do a whole lot of work at getting people off the hook of personal responsibility.
II. The Actual Problem Has a Name, and It’s Not “Hallucination”
Let’s be precise about what actually happened when a lawyer filed a brief containing citations to cases that don’t exist: a lawyer signed and submitted a document they had not read. That’s it. That’s the whole story.
The AI didn’t file the brief. The AI didn’t have a law license. The AI didn’t swear an oath, and it didn’t certify anything to the court. The lawyer did all of those things—and apparently did them without reading what they were certifying.
This has a name. Rule 11 of the Federal Rules of Civil Procedure requires that an attorney certify, after an inquiry reasonable under the circumstances, that the legal contentions in a filing are warranted by existing law.4 Courts have read that requirement to include actually checking whether the law you’re citing is still good law—failing to run a citator check has been held to violate Rule 11 on its own.5 ABA Model Rule 1.1 requires that lawyers provide competent representation, which includes the legal knowledge, skill, thoroughness, and preparation reasonably necessary for the representation.6 Rule 3.3 requires candor toward the tribunal—lawyers may not make false statements of law to a court, and they have an affirmative duty to correct one if they discover it.7 These rules did not change when generative AI broadly launched. They did not include an exception for outputs you didn’t generate yourself. They have never included such an exception, which is why we don’t typically accept “my paralegal wrote it” as a defense either.
What we are watching, dressed up in technical language, is a failure of basic professional responsibility. A doctor who countersigns a lab result they haven’t reviewed is not a victim of laboratory error. A structural engineer who stamps drawings they didn’t check is not a victim of drafting software. And a lawyer who files a brief they didn’t read is not a victim of AI hallucination. In each case, the professional had a duty to verify, possessed the means to verify, and chose not to. The tool that produced the underlying work product is beside the point.
The hallucination framing is doing exactly the work it’s designed to do: it makes the failure sound technical, mysterious, and external to the lawyer’s control. It isn’t any of those things.
III. The Literacy Failure That Made the PR Failure Possible
If the professional responsibility failure is the immediate problem, there’s a second failure nested underneath it that created the conditions for the first: a significant portion of the legal profession does not understand what AI tools actually do, and that ignorance is not evenly distributed across risk levels.
Here’s what a large language model is not doing when it drafts a brief: it is not retrieving documents from a legal database, reading them, and exercising legal judgement about them. It is predicting text—generating output that is statistically consistent with the patterns in its training data, which means it produces text that looks like a legal citation, formatted correctly, sounding authoritative, because it has been trained on enormous quantities of legal writing that contains real citations formatted exactly that way. It is not lying. It is not hallucinating in the clinical sense. It is doing precisely what it was designed to do, and what it produced is plausible-sounding output that happens to be wrong.
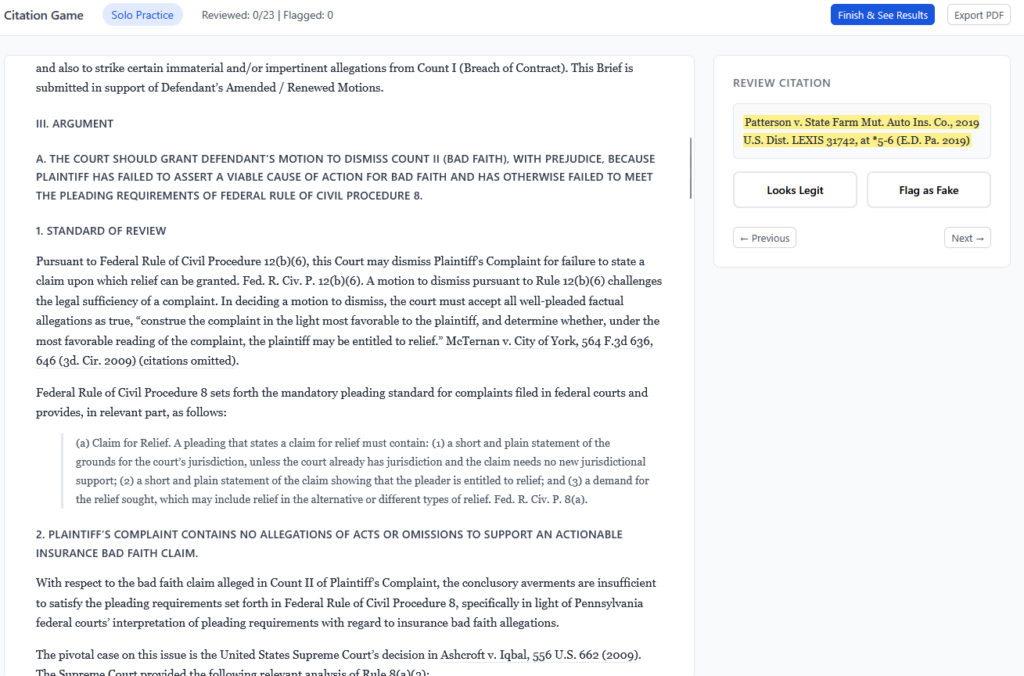
A practitioner who understood this would approach AI-drafted citations the way a careful researcher approaches any secondary source: as a starting point that requires verification, not a deliverable that requires a signature. The verification step isn’t technically demanding. Every major legal research platform provides citation-checking tools. At minimum, you can pull the case. The professional responsibility violation and the literacy failure are not separate problems—the literacy failure is why the professional responsibility failure seemed acceptable.
This matters because the positive case is genuinely strong. There are countless ways to use AI in legal work that carry no meaningful citation risk at all: drafting and editing prose, synthesizing large records, generating research memos that a lawyer then verifies, preparing for negotiation, managing correspondence. The citation problem is specific to one use case—asking an LLM to generate citations as if it were a legal research database—and it is nearly entirely preventable by one habit: read and verify what you’re about to put your name on. That habit isn’t new. It predates AI by at least 200 years.8
IV. The Ban Won’t Fix It—And May Make It Worse
Prohibition is a technology-governance strategy with a well-documented track record, and that track record is not good. Banning AI from court filings does not eliminate AI use in legal practice. It eliminates disclosed AI use. Lawyers who are currently using these tools carelessly will continue using them—without oversight, without any professional incentive to develop better habits, and without the profession building the infrastructure to train or regulate responsible use. The lawyers who will comply with a ban are, by and large, the ones who would have checked their citations anyway.
There’s a market dimension to this that deserves attention. A significant and growing number of legal AI products are, in technical terms, wrappers around general-purpose language models, with some legal-specific training added in, and rebranded for legal audiences and sold at prices that reflect the prestige of the legal market rather than the sophistication of the underlying technology.9 Some of these products are sold aggressively to law firms and legal departments whose leadership is precisely credulous enough to be impressed by confident technical language and precisely ignorant enough not to notice when the product doesn’t actually do what’s claimed. Even where the underlying technology has matured, the institutions deploying it routinely fail to build the governance, training, and validation infrastructure that responsible use requires—a gap industry observers increasingly identify as the actual point of failure, not the model itself.10 The people who genuinely understand these systems are rarely the ones in the purchasing meetings. The result is that firms spend significant money on tools that don’t reduce AI risk—they just make AI risk more expensive. An outright ban accelerates this dynamic: it pushes usage further from visibility and toward unaccountable, unvetted, often overpriced private solutions that serve the vendor’s interests more reliably than the client’s.
The access-to-justice dimension is the one that should be keeping judges up at night, and it’s conspicuously absent from most ban discussions. AI tools used responsibly have genuine potential to reduce the cost of legal services, extend the reach of competent representation, and close gaps that have existed in this system for generations. The people who most need that closing are not the ones with BigLaw retainers. Banning AI doesn’t protect those clients. It protects the status quo that was already failing them.
V. What Should Actually Happen
The legal profession has a governance structure. It has bar associations, ethics rules, judicial authority, and law schools that control entry into the profession. These are not weak institutions—they are the ones that decide who gets an education, a license, what competence means, and what consequences attach to failing to meet it. The question is not whether they have the authority to address this problem. They do. The question is whether they are willing to use that authority to address the actual problem rather than the more comfortable one.
Enforcing existing ethics rules against the lawyers who filed unchecked briefs is not complicated. The rules already cover this. What appears to be missing is the will to apply them without the alibi of “the AI did it”—which, as established, is not a defense that survives scrutiny under the Federal Rules of Civil Procedure or the ABA Model Rules.
Beyond enforcement, the more durable fix is curricular. A law school that does not provide students with grounded, accurate AI literacy—not vendor-sponsored tutorials, not hand-wringing seminars, but genuine instruction in what these tools do, what they don’t do, and what professional responsibility looks like in a practice environment where they are ubiquitous—is not preparing lawyers for the profession they are entering. That is a failure of institutional responsibility, and it is one that prospective students, faculty, and accreditors are in a position to name and pressure. It will be worth watching, over the next several years, whether bar admission data and practice location choices start to reflect attorneys voting with their feet toward jurisdictions that have developed coherent AI frameworks rather than reflexive bans.
Law librarians reading this are not bystanders to any of it. Legal research instruction, information literacy, and the professional competence to evaluate and verify sources have always been the core of what law librarians teach and model. The AI context doesn’t change that mission—it makes it more urgent and more visible.
The lawyers who know how to use these tools carefully are, in a meaningful number of cases, the ones who received genuine legal research education from people who cared about getting it right. That instruction doesn’t happen without adequate staffing, and law library staffing has been moving in exactly the wrong direction for years. Law librarians are among the most underpaid professionals in legal education relative to the expertise they hold and the institutional function they serve.11 Positions go unfilled. Existing staff absorb expanding mandates without additional support or compensation. Effective leadership capable of building and sustaining a real AI literacy curriculum is not inevitable—it has to be resourced, prioritized, and protected. You cannot instruct a generation of lawyers in responsible AI use with a skeleton crew and a budget that hasn’t kept pace with the problem. If law schools are serious about preparing students for modern practice, the library isn’t where you find efficiencies. It’s where you invest.
The legal profession does not need an AI ban. It needs accountability applied to the people who failed to meet existing standards, literacy built into the pipeline before those people get licensed, and the collective intellectual honesty to stop blaming the tool for choices that were made by lawyers. What we are watching is not a new problem created by new technology.12 It is an old problem—lawyers not reading what they sign—that technology has finally made impossible to ignore.13 That is, if nothing else, an opportunity. The question is whether the profession takes it.
Charlie (she/her) Amiot (rhymes w/cameo) is a former legal research instructor and reference librarian who currently writes What Congress Should Be Reading, a newsletter tracking Congressional Research Service reports for a general audience. An expert in government information, her work has examined the legislative history of CRS and public access to government information, and she currently serves as Secretary of the Depository Library Council. She also has a longstanding interest in legal AI, with deep, self-directed expertise built through sustained study and engagement with both practitioners and the tools themselves.
- I’m sure many readers are familiar with Damien Charlotin’s database of so-called AI Hallucination Cases (https://www.damiencharlotin.com/hallucinations/). Containing judicial opinions only, the database already holds 1600 references. ↩︎
- Escott, D. J. (2025, December 8). From hallucination to indictment: The criminalization of the AI-enabled lie. Law360 Canada. https://www.law360.ca/ca/articles/2419185/from-hallucination-to-indictment-the-criminalization-of-the-ai-enabled-lie. Koebler, J. (2025, Sept. 30). 18 Lawyers Caught Using AI Explain Why They Did It. 404media. https://www.404media.co/18-lawyers-caught-using-ai-explain-why-they-did-it/?ref=daily-stories-newsletter. ↩︎
- Goldfish actually have great memories. They can be relatively quickly trained to play basketball on command. But in the Ted Lasso universe they are upsettingly portrayed as idiots with a three-second memory who could be outsmarted by Dory. Alas, is that a hallucination? ↩︎
- Fed. R. Civ. P. 11(b)(2). https://www.law.cornell.edu/rules/frcp/rule_11. ↩︎
- Deters v. Davis, No. CIV.A. 3:11-02-DCR, 2011 WL 2417055 (E.D. Ky. June 13, 2011). See also, Cody James, Citators in the AI Age: Preserving the Human Component Through Court-Created Citators, 118 Law Lib. J. 66, 71-73 (2026). ↩︎
- Model Rules of Prof’l Conduct r. 1.1 (Am. Bar Ass’n 2023), https://www.americanbar.org/groups/professional_responsibility/publications/model_rules_of_professional_conduct/rule_1_1_competence/; see also, r. 1.1, Comment 5, https://www.americanbar.org/groups/professional_responsibility/publications/model_rules_of_professional_conduct/rule_1_1_competence/comment_on_rule_1_1/. ↩︎
- Model Rules of Prof’l Conduct r. 3.3 (Am. Bar Ass’n 2023). https://www.americanbar.org/groups/professional_responsibility/publications/model_rules_of_professional_conduct/rule_3_3_candor_toward_the_tribunal/. ↩︎
- Cody James, Citators in the AI Age: Preserving the Human Component Through Court-Created Citators, 118 Law Lib. J. 66, 68-69 (2026). ↩︎
- Some believe instead that the term harness is more accurate; I am more than willing to accept that definition and the examples proffered. Nicola Shaver, AI Harnesses: The Layer Where Differentiation Crystallizes, Legaltech Hub (May 11, 2026). https://www.legaltechnologyhub.com/contents/ai-harnesses-the-layer-where-differentiation-crystallizes/ I use the term wrapper here the way Shaver and Ethan Mollick use harness (https://www.oneusefulthing.org/p/a-guide-to-which-ai-to-use-in-the). ↩︎
- Cate Giordano, Legalweek 2026: AI in Legal Has a Deployment Problem, Legaltech Hub (Mar. 24, 2026), https://www.legaltechnologyhub.com/contents/legalweek-2026-ai-in-legal-has-a-deployment-problem. ↩︎
- Olivia Smith Schlinck, Academic Law Librarians Are Paid 47% Less Than Their Faculty Counterparts (Feb. 4, 2022), https://ripslawlibrarian.wordpress.com/2022/02/04/academic-law-librarians-are-paid-47-less-than-their-faculty-counterparts/. ↩︎
- Samantha Cole, Watch These Judges Rip Into Lawyers For Citing Cases That Don’t Exist, 404media (June 4, 2026), https://www.404media.co/new-york-court-ai-citations-landberg-case/; J. Koebler, Judge Learns Lawyers on Both Sides of Case Used AI, Cancels Trial, Kicks Everyone Off the Case, 404media (June 9, 2026), https://www.404media.co/judge-learns-lawyers-on-both-sides-of-case-used-ai-cancels-trial-kicks-everyone-off-the-case/. ↩︎
- OJ Simpson Murder Trial – Shepard’s clip https://www.youtube.com/watch?v=QFOY0Glg0gU. ↩︎