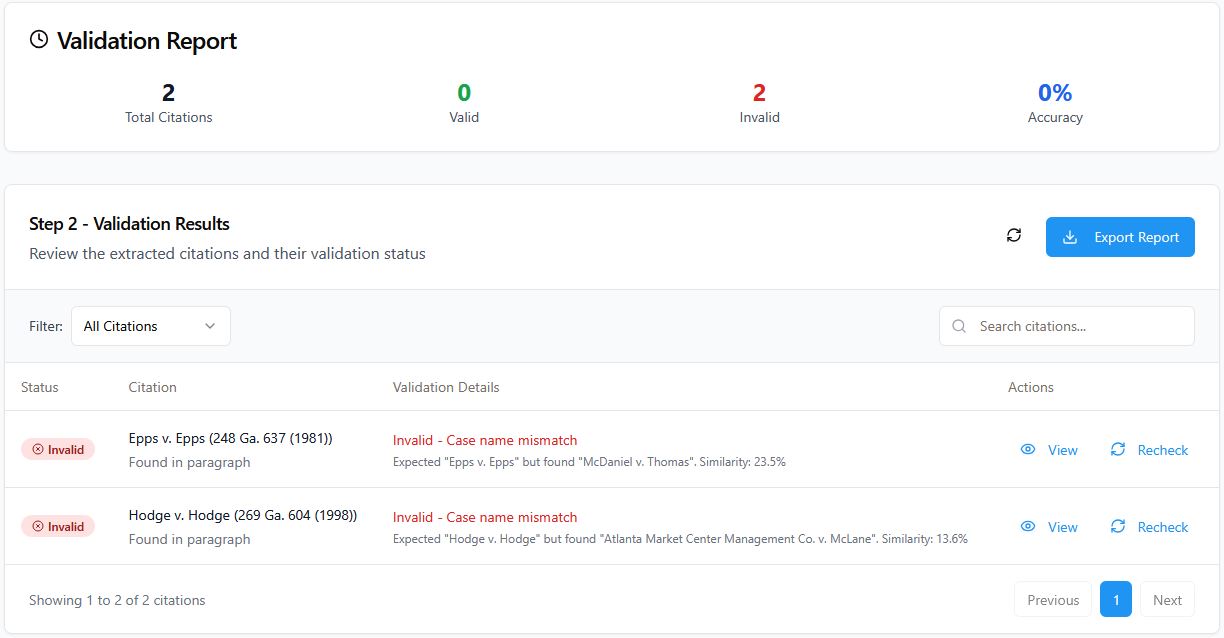
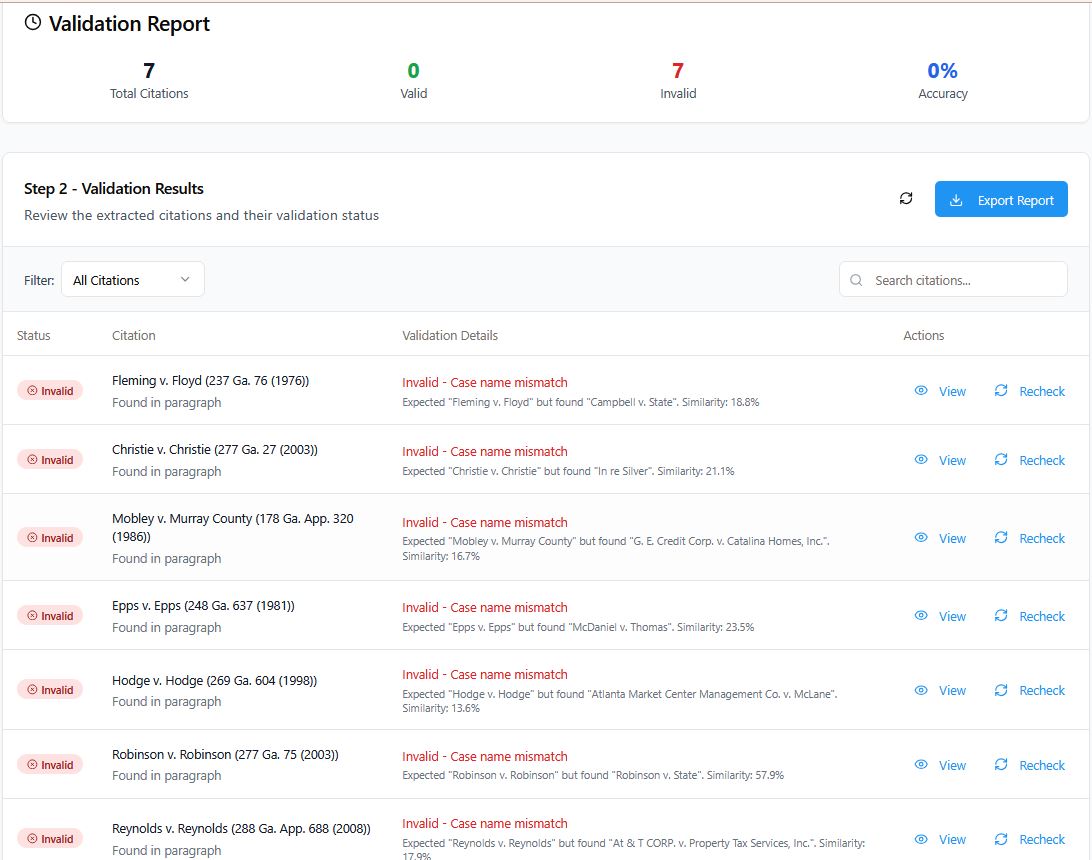
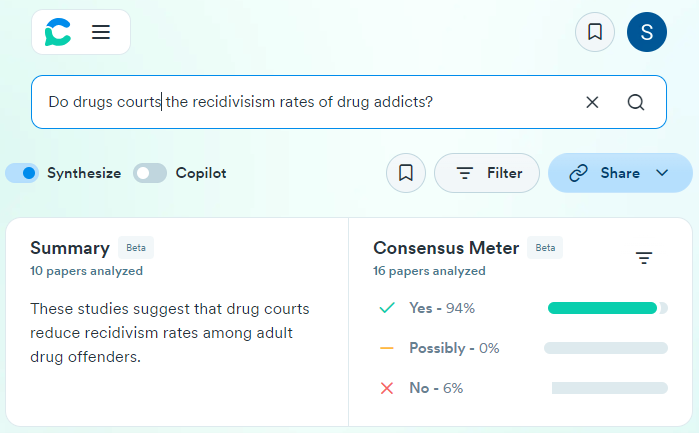
This post is brought to you by ChatGPT’s Deep Research. It produced this report after about 10 minutes of thinking and searching online (sources in the footnotes). I have also used it for a couple of fairly complex legal research queries and it produces the equivalent of an article from a treatise – they were about 10-15 pages and had 20+ footnotes. One of them was a bankruptcy question and, interestingly, it cited to Collier on Bankruptcy. I looked up the citation in Lexis and it was accurate…
You’ll notice in the following post that it seems to cite to the University of Arizona quite a lot. I would assume this is because their web presence is either highly SEO optimized (easy to find) or they do not have a robots.txt in their footer (yet) but I’m interested to hear if you have a different hypothesis.
Deepseek Output:
Great, I will conduct a comprehensive review of how AI is transforming U.S. law schools from 2023-2025. This will include changes in teaching methods, faculty and law librarian practices, and collection development in law libraries. I’ll draw from trusted sources such as LawNext, GeekLawBlog, Artificial Judgment, Bespacific, Legal Technology, and the ABA’s tech section. The blog post will be structured with clear headings and span approximately three pages.
I’ll notify you when the research is complete.
How AI is Reshaping U.S. Law Schools (2023–2025)
Artificial intelligence has rapidly moved from science fiction into the everyday realities of legal education. Since the emergence of powerful generative AI tools like OpenAI’s ChatGPT in late 2022, U.S. law schools have been grappling with how to adapt. Between 2023 and 2025, AI has begun to reshape law schools in profound ways – from what and how students learn, to how professors and librarians do their jobs, to the very makeup of library resources. Below, we explore these changes in detail.
Transforming Legal Education with AI
Curriculum Integration: Law schools are increasingly weaving AI into the curriculum. A survey by the ABA’s Task Force on Law and Artificial Intelligence in early 2024 found that 55% of responding schools offer courses dedicated to AI, and 83% offer some opportunities (like clinics or projects) for students to learn to use AI tools (Recent Reports of Law Schools’ AI Adoption Have Been Greatly Exaggerated | LawSites) (3 Keys for Law Students Using AI) (It’s worth noting the survey had a low response rate, so the true numbers across all schools are likely lower (Recent Reports of Law Schools’ AI Adoption Have Been Greatly Exaggerated | LawSites) ) Even so, the trend is clear: a growing number of law schools now teach about AI and law. By mid-2024, an independent tally found at least 62 U.S. law schools (roughly 31%) offering courses on AI and the law, with nearly 100 AI-related law courses between them (Remember that ABA Survey of Law Schools with AI Classes? This May Be A More Accurate List | LawSites) (Remember that ABA Survey of Law Schools with AI Classes? This May Be A More Accurate List | LawSites) This represents a sharp increase from just a few years ago when such courses were rare. In a high-profile move, Case Western Reserve University School of Law announced in 2025 that all first-year students must complete a certification in legal AI. Their new mandatory program, “Introduction to AI and the Law,” gives 1Ls hands-on experience with AI-powered legal tools and explores the evolving landscape of AI regulation and ethics (Case Western Reserve University School of Law to require legal AI education certification | beSpacific) As Case Western’s associate dean Avidan Cover put it, “By integrating AI education into the foundational curriculum, we are… empowering our students with the tools and knowledge they need to navigate and lead in a technology-driven profession” (Case Western Reserve University School of Law to require legal AI education certification | beSpacific) These steps signal a recognition that tomorrow’s lawyers must understand AI’s role in law.
Teaching Methodologies: Alongside new courses, professors are experimenting with AI-integrated teaching methods. Educators are realizing that students need practical skills to work with AI. Some law professors now design assignments where students collaborate with or critique AI. For example, instructors have reported class exercises where students use a tool like ChatGPT to draft a portion of a memo or brief, then have to critically evaluate and improve the AI’s work (Teaching Law In The Age Of Generative AI) Others have students “role-play with chatbots” – treating an AI as a fake client or opposing counsel in simulations – to sharpen interviewing and counseling skills (Teaching Law In The Age Of Generative AI) These innovative exercises teach students how to use AI as a helper while also spotting its weaknesses. “AI is already having a significant impact on legal education and is likely to result in additional changes in the years ahead,” noted the ABA’s report, which observed that law schools are evolving their pedagogy to meet the demands of a tech-shaped profession (3 Keys for Law Students Using AI) Professors are also increasingly discussing the ethics and pitfalls of AI in class. For instance, students may be asked to debate the responsible use of generative AI in practice – covering issues like bias, confidentiality, and the unreliability of “hallucinated” (fabricated) citations or facts.
Student Assessments and Academic Integrity: The rise of AI has forced law schools to rethink exams and evaluations. Early on, there was panic that ChatGPT would be “the death of the essay” – that students could simply have a bot write their papers or exam answers (Experiments with ChatGPT: Don’t Panic, the Robots Are Not Writing Your Students’ Legal Memos | 3 Geeks and a Law Blog) In response, many schools rushed to set policies on AI-assisted work. A Kaplan survey found that by late 2024 about 45% of law schools explicitly banned generative AI for writing admissions essays, while only 1% officially allowed it (the rest had no formal policy) ( This law school is among the 1% that allow use of AI to write admissions essays ) ( This law school is among the 1% that allow use of AI to write admissions essays ) Some law professors similarly banned AI use on assignments unless disclosed, treating undisclosed use as plagiarism. However, as faculty gained experience, outright panic has given way to a more measured approach. Notably, professors at University of Minnesota Law School tested ChatGPT on four real law exams in 2023 – and the AI averaged a C+ grade (around the bottom 20% of the class) (Experiments with ChatGPT: Don’t Panic, the Robots Are Not Writing Your Students’ Legal Memos | 3 Geeks and a Law Blog) On one hand, ChatGPT’s answers showed *“a strong grasp of basic legal rules” and solid organization, mimicking a competent but not exceptional student (Experiments with ChatGPT: Don’t Panic, the Robots Are Not Writing Your Students’ Legal Memos | 3 Geeks and a Law Blog) * On the other hand, when questions required deeper analysis or reference to specific cases, ChatGPT often failed spectacularly, sometimes earning the worst score in the class (Experiments with ChatGPT: Don’t Panic, the Robots Are Not Writing Your Students’ Legal Memos | 3 Geeks and a Law Blog) These findings reassured faculty that current AI isn’t (yet) acing law school. As one legal writing professor noted, AI-generated essays tend to be *superficial – correct on black-letter law, but poor at issue-spotting and applying law to facts in nuanced ways (Experiments with ChatGPT: Don’t Panic, the Robots Are Not Writing Your Students’ Legal Memos | 3 Geeks and a Law Blog) . Knowing this, some instructors now design assessments that emphasize critical thinking and personalized analysis that AI can’t easily mimic. Others allow limited use of AI for preliminary drafting or idea-generation, so long as students cite it and then significantly edit the work. The overarching goal is to maintain academic integrity while also recognizing that learning to supervise AI might be a valuable skill in itself. In fact, a growing view is that students should graduate with experience in using AI appropriately rather than with a complete prohibition. As one law dean remarked, a “material number of law schools are responding aggressively” to AI’s rise, viewing these early adaptations as “a sign of what’s to come in terms of legal education” (Recent Reports of Law Schools’ AI Adoption Have Been Greatly Exaggerated | LawSites)
Faculty and Law Librarians Adapt to AI
It’s not just students adjusting – professors and law librarians are also leveraging AI to streamline their work and enhance their scholarship. Law faculty have discovered that generative AI can assist with some of their most time-consuming tasks. For instance, professors in various disciplines have used tools like ChatGPT as a research assistant – generating initial literature reviews, summarizing cases or articles, and even brainstorming novel legal arguments. In one headline-grabbing experiment, a U.S. law professor (Andrew Perlman of Suffolk University Law School) co-wrote an entire law review article with ChatGPT in 2024, asking the AI to “develop a novel conception of the future of legal scholarship.” The resulting paper – with the AI’s contributions clearly marked – argued that AI will expand the scale and scope of academic legal writing, allowing scholars to iterate ideas faster (Recent Reports of Law Schools’ AI Adoption Have Been Greatly Exaggerated | LawSites) This “AI-written” article was deliberately provocative, but it underscores how some faculty are testing AI’s capabilities in scholarship. Even professors who don’t go that far are finding smaller ways to use AI day-to-day. For example, drafting and editing: a professor might have ChatGPT generate a rough syllabus paragraph or multiple-choice questions for an exam, then refine them. Others report using AI to help grade by, say, inputting a model answer and a student answer and asking the AI to compare – though due to reliability concerns, AI isn’t replacing human graders, just assisting as a second pair of eyes.
Faculty are also harnessing AI for administrative efficiency. Generative AI can quickly produce first drafts of routine emails, recommendation letters, or research grant applications, which professors can then personalize. This helps cut down on rote writing tasks. Importantly, professors approach these uses with caution – verifying facts and ensuring any AI-generated text is accurate and in their own voice. As one might expect, tech-savvy law professors have also started incorporating AI topics into their research agendas. Legal scholars are producing a surge of articles on AI’s implications for everything from intellectual property to criminal justice. In doing so, many use AI tools to analyze data (for example, using machine learning to parse large sets of court decisions). In short, the professoriate is learning to work smarter with AI, treating it as a junior research assistant that never sleeps, albeit one that requires heavy supervision.
Meanwhile, law librarians – often the vanguard of technology in legal academia – have been quick to explore AI’s potential in libraries. “Law librarians have always been early technology adopters and trainers,” notes Cas Laskowski, a research and instruction librarian at Duke, “we are proud to launch [projects] focusing on AI and how libraries can remain… equitable community anchors in our increasingly tech-driven world.” (Law Libraries Launch Initiative to Prepare for Artificial Intelligence Future | University of Arizona Law) One early and practical use of AI for librarians is summarizing and organizing information. Law librarians are skilled at finding vast amounts of information for faculty and students, but summarizing that trove can be labor-intensive. In early 2023, Greg Lambert (a law librarian and blogger) tried using GPT-3.5 to automatically summarize legal news and podcasts. He was “impressed” with the results, noting that “any tool that would help librarians synthesize information in a useful way is a welcome tool” in an environment where one librarian may support hundreds of attorneys or students (What a Law Librarian Does with AI Tools like ChatGPT – Organize and Summarize | 3 Geeks and a Law Blog) By having an AI quickly generate a concise summary of, say, a 50-page report or a set of new case law updates, librarians can save time and serve their patrons faster. Similarly, AI can help organize data – some libraries have experimented with AI to classify documents or tag resources with relevant topics, augmenting traditional cataloging.
Law librarians are also leveraging AI to assist faculty and students in legal research. As new AI-driven legal research platforms emerged (from startups and the big vendors), librarians took on the role of testers and guides. In 2023 and 2024, many law librarians ran experiments with tools like Harvey, Casetext’s CoCounsel, Westlaw Precision with AI, and Lexis+ AI to see how they perform. Their dual aim: to advise users on the tools’ effectiveness and to flag pitfalls. Notably, when LexisNexis rolled out its generative AI legal research assistant (“Lexis+ AI”), librarians and professors scrutinized its output. Early tests were not entirely reassuring – one Canadian law professor found that Lexis+ AI’s results were “riddled with mistakes”, including citing non-existent legislation and mischaracterizing cases, leading him to conclude it “should not be used by law students yet” (Canadian law professor gives Lexis+ AI “a failing grade” – LexisNexis responds – Legal IT Insider) (Canadian law professor gives Lexis+ AI “a failing grade” – LexisNexis responds – Legal IT Insider) U.S. law librarians have reported similar concerns with other AI tools “hallucinating” citations or facts. As a result, academic law librarians have been busy updating research training for students: they teach not just how to use these new AI research features, but also how to double-check AI outputs against reliable sources. In some law schools, librarians created guides and tutorials on the dos and don’ts of generative AI in legal research – emphasizing that these tools can save time only if used carefully and not as a substitute for traditional verification (Experiments with ChatGPT: Don’t Panic, the Robots Are Not Writing Your Students’ Legal Memos | 3 Geeks and a Law Blog) (Experiments with ChatGPT: Don’t Panic, the Robots Are Not Writing Your Students’ Legal Memos | 3 Geeks and a Law Blog)
Finally, on the administrative side, AI is helping law librarians behind the scenes. Some libraries are using AI-driven analytics to make decisions about collection usage and budgeting. For example, AI can analyze which databases or journals are underused (to consider cancellation) or predict what topics will be in demand, informing acquisition decisions. Library staff are also exploring AI to automate repetitive tasks like updating citation metadata, checking links, or even answering common patron questions via chatbots. All these adaptations free up librarians to focus on higher-level tasks, like one-on-one research consultations and teaching – the things that AI can’t easily replace.
AI in Law Library Collections and Research
The very collections and databases that law libraries manage are evolving thanks to AI. Not long ago, a law library’s idea of high-tech was providing online databases like Westlaw, Lexis, or HeinOnline. By 2023–2025, those databases themselves have gotten smarter, and libraries are acquiring completely new AI-based resources.
AI-Powered Research Tools: A major development has been the integration of generative AI into legal research platforms. Both Westlaw and LexisNexis launched AI-enhanced research offerings in 2023, allowing users to input natural-language questions and receive narrative answers or brief drafts alongside the usual list of sources. For example, Lexis+ AI can draft a legal memorandum based on a query, using the content of its vast database to generate an answer (with cited sources). These tools promise to save time by synthesizing cases and statutes on a given issue. Law libraries, as the gatekeepers to research services, have been evaluating these tools for inclusion in their digital collections. By late 2024, many law libraries were running pilot programs with generative AI research tools, often in partnership with the vendors. Law librarians must decide: do these tools provide reliable value for students and faculty? Given the mixed early reviews (with accuracy concerns like those noted above), libraries are adopting a cautious approach – often providing access to AI research tools on an optional basis and collecting feedback before fully integrating them into the curriculum. Still, the direction is set. As one legal tech commentator observed in 2024, “New and emerging AI technologies, such as GPT models, have the potential to reshape the legal landscape… Law schools should consider updating their curriculum to reflect the growing use of AI in the legal field.” (AI vs Law Schools: The Cost of Ignoring the Future) (AI vs Law Schools: The Cost of Ignoring the Future) In practice, this means law libraries will increasingly offer AI-driven databases alongside traditional resources, ensuring students learn how to use cutting-edge tools like brief analyzers, contract review AI, and chat-style legal Q&A systems.
Digital Collections & Knowledge Management: Beyond commercial databases, law libraries are using AI to enhance their own institutional repositories and archives. Digital collections of case law, scholarship, or historical legal materials can be made more accessible with AI. For instance, some libraries are experimenting with natural language search or AI chat interfaces for their archives, so a student could query an alumni brief bank or a faculty publications repository in plain English and get relevant results summarized. AI can also assist in transcribing and organizing audio/visual content (like recordings of lectures or court oral arguments) making them searchable text for researchers. In collection development, librarians are intrigued by AI tools that can predict research trends – if an AI analyzes millions of data points (news, scholarly articles, court dockets) and predicts a surge in, say, climate law litigation, a library might proactively acquire more in that area. While such predictive collection development is still emerging, it’s on the horizon.
Acquisitions and Budgeting: The role of AI has also reached the budgeting and acquisition strategies of law libraries. AI-driven analytics help librarians identify which resources provide the most value. By automatically compiling usage statistics and user feedback, AI can suggest which subscriptions to renew or cancel. Some law library systems use machine learning to recommend new titles based on current collection and usage patterns, akin to how e-commerce sites suggest products. This makes collection development more data-driven. Additionally, the cost of new AI tools is a factor – many of these advanced research platforms come at premium prices. Law libraries must justify these costs by demonstrating the educational value. The collaborative initiative “Future of Law Libraries: AI, Opportunities, and Advancement,” led by several law schools in 2023, is one example of libraries banding together to tackle these questions (Law Libraries Launch Initiative to Prepare for Artificial Intelligence Future | University of Arizona Law) Through a series of nationwide roundtables, law library leaders are sharing strategies on budgeting for AI and negotiating with vendors, as well as brainstorming best practices for training users on these resources (Law Libraries Launch Initiative to Prepare for Artificial Intelligence Future | University of Arizona Law) As Teresa Miguel-Stearns (director of University of Arizona’s law library) explained, “Artificial intelligence promises to revolutionize how law libraries function and provide value… Through insightful discussions, we hope to identify constructive ways law libraries can plan for and utilize AI to improve access to legal information [and] enhance legal education.” (Law Libraries Launch Initiative to Prepare for Artificial Intelligence Future | University of Arizona Law) In short, collection development policies are being updated to account for AI – both as content (buying AI tools) and as methodology (using AI to make decisions).
Maintaining Trust and Accuracy: A core mission of law libraries is to provide trustworthy legal information. Thus, librarians are carefully monitoring the accuracy of AI in research. As noted, early adopters found that generative AI legal tools sometimes generate fake citations or flawed analysis, which could mislead the unwary researcher. To protect the integrity of the library’s offerings, some law libraries have set usage guidelines for AI tools: for example, warning students that AI answers are only a starting point and must be verified against primary sources. A few libraries even require users to sign in to use certain AI tools, so they can track outcomes and intervene if needed. Publishers are responding to these concerns too – for instance, newer versions of legal AI systems are emphasizing transparency by providing hyperlinks to sources for every assertion, and some use “embedded reference checking” to alert if a cited case seems inconsistent with the proposition. Law libraries are keenly evaluating these features. The end goal is to integrate AI into collections without compromising on reliability. In the words of one law school technology director, it’s about finding ways to “leverage AI for law libraries in the future” while avoiding the mistakes of unchecked automation (Law Libraries Launch Initiative to Prepare for Artificial Intelligence Future | University of Arizona Law)
Conclusion
From 2023 to 2025, the influence of AI on U.S. law schools has grown from a novelty to an impending reality that no law school can ignore. In legal education, AI is driving changes in what is taught (more tech and AI law content), how it’s taught (new teaching methods and careful assessment policies), and what skills students graduate with (hopefully, the ability to use AI tools ethically and effectively). Faculty and librarians are not standing idle; they are adopting AI to augment their research, teaching, and administrative duties, even as they remain cautious about its limits. Law libraries, often the heart of a law school, are transforming their collections and services to include powerful AI resources, all while upholding the standards of accuracy and thoroughness that define legal research.
Crucially, this period has also seen a shift in mindset: rather than view AI only as a threat (to academic honesty or to jobs), many in legal education now see it as an opportunity. As one ABA tech report observed, ignoring AI is not an option – the future of law will be shaped by those attorneys who are competent with technology (AI vs Law Schools: The Cost of Ignoring the Future) Law schools that adapt now are positioning their graduates to be those competent attorneys. In the years ahead, we can expect AI to be as commonplace in law classrooms and libraries as Westlaw and casebooks have been for decades. The reshaping of law schools by AI is well underway, and 2023–2025 has been just the beginning of that profound evolution.
Sources:
- Ambrogi, Bob. “Recent Reports of Law Schools’ AI Adoption Have Been Greatly Exaggerated.” LawNext, July 2, 2024 (Recent Reports of Law Schools’ AI Adoption Have Been Greatly Exaggerated | LawSites) (Recent Reports of Law Schools’ AI Adoption Have Been Greatly Exaggerated | LawSites)
- Ambrogi, Bob. “ABA Survey of Law Schools with AI Classes – A More Accurate List.” LawNext, Aug. 1, 2024 (Remember that ABA Survey of Law Schools with AI Classes? This May Be A More Accurate List | LawSites)
- Case Western Reserve Univ. School of Law. “Case Western Reserve… to require legal AI education certification.” beSpacific, Jan. 23, 2025 (Case Western Reserve University School of Law to require legal AI education certification | beSpacific) (Case Western Reserve University School of Law to require legal AI education certification | beSpacific)
- Bliss, John. “Teaching Law in the Age of Generative AI.” Jurimetrics, Winter 2024 (Teaching Law In The Age Of Generative AI)
- Lambert, Greg (Jennifer Wondracek & Rebecca Rich). “Experiments with ChatGPT: Don’t Panic…” 3 Geeks and a Law Blog, Jan. 30, 2023 (Experiments with ChatGPT: Don’t Panic, the Robots Are Not Writing Your Students’ Legal Memos | 3 Geeks and a Law Blog) (Experiments with ChatGPT: Don’t Panic, the Robots Are Not Writing Your Students’ Legal Memos | 3 Geeks and a Law Blog)
- Lambert, Greg. “What a Law Librarian Does with AI Tools like ChatGPT.” 3 Geeks and a Law Blog, Jan. 13, 2023 (What a Law Librarian Does with AI Tools like ChatGPT – Organize and Summarize | 3 Geeks and a Law Blog)
- Miguel-Stearns, Teresa, et al. “Law Libraries Launch Initiative to Prepare for AI Future.” University of Arizona Law News, Sept. 6, 2023 (Law Libraries Launch Initiative to Prepare for Artificial Intelligence Future | University of Arizona Law) (Law Libraries Launch Initiative to Prepare for Artificial Intelligence Future | University of Arizona Law)
- Hill, Caroline. “Canadian law professor gives Lexis+ AI a ‘failing grade’ – LexisNexis responds.” Legal Technology News, Nov. 18, 2024 (Canadian law professor gives Lexis+ AI “a failing grade” – LexisNexis responds – Legal IT Insider)
- Butalia, Manit. “AI vs Law Schools: The Cost of Ignoring the Future.” Law Technology Today (ABA), Nov. 26, 2024 (AI vs Law Schools: The Cost of Ignoring the Future) (AI vs Law Schools: The Cost of Ignoring the Future)
- Cassens Weiss, Debra. “Majority of law schools have no policy on using AI for admissions essays.” ABA Journal, Oct. 9, 2024 ( This law school is among the 1% that allow use of AI to write admissions essays )