
Some of you reading this may be skeptical that these new AI technologies are 1) within your skillset and/or 2) worth the effort to learn. I’m the congenital optimist who is here to win you over. These tools are on the verge of revolutionizing the field of law (once they get out of their prototype phase) and I can’t think of a better group of people on law school campuses, in government organizations, and in law firms to evaluate and implement these technologies. Law Librarians (traditionally) have two crucial skill sets that make us well-suited to take the lead here:
- We understand how information is organized and
- We understand how information is used in the research and practice of law.
This is an AI Youtuber with ~70k subscribers who develops and trains LLMs from scratch. Do you see what he has listed as the number one discipline that people need to learn to use these tools? Computer Science skills rank third on his list compared to “Librarianship and Information Science” at #1.
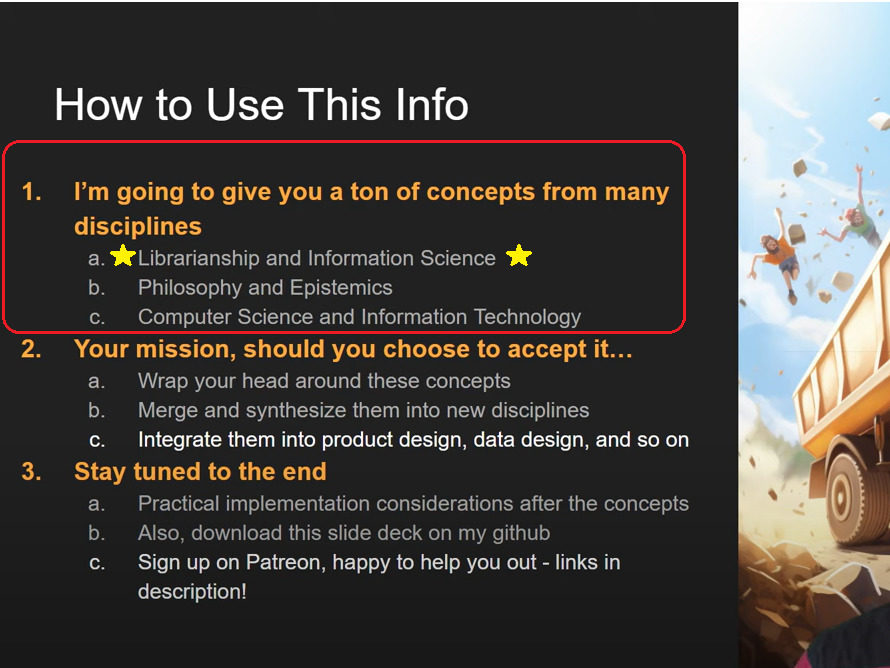
This dude gets it.
Many of the tips that David Shapiro provides in that video for people creating custom LLMs will be absolutely obvious to law librarians because we live and breathe these every day at our jobs: taxonomies, data organization, “source of truth,” etc. Whether in the tech services department or research instruction, we are well-versed in organizing and finding information.
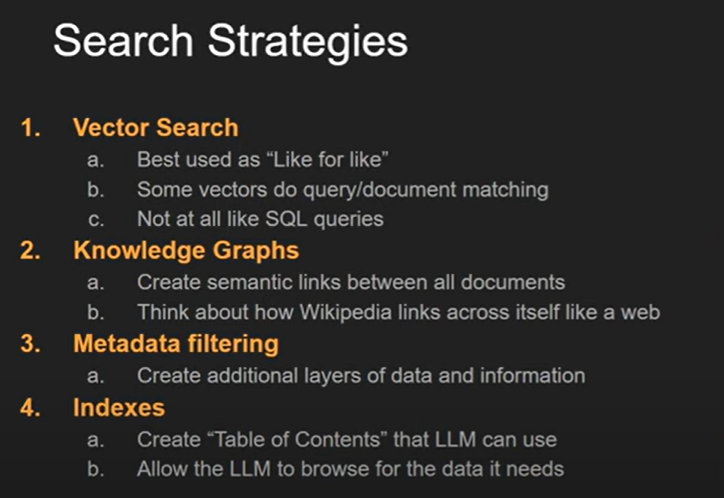
We already have many of the data structures in place that could be easily used by these technologies. Besides constructing the initial models, our role will be pivotal in continuously updating and assessing their effectiveness. Moreover, we will provide vital guidance on the proper utilization of these tools.
Does this list look like something your Technical Services department does? Can you think of anyone else in your organization who would be better at making knowledge graphs, indexes, or tables of contents for legal materials? Who would be better suited than your Research and Instruction team to teach newcomers how to interact with these tools to get the information that they need? Who in your organization is best positioned to teach (or already teaches) information literacy? I would argue that nobody can do it better than law librarians (not even computer science people).
Now What?
Let’s mobilize a push to collaborate on these tools. We need to get groups of law librarians together who are interested in rolling up their sleeves and digging into the nitty-gritty of creating, auditing, and using LLMs. I am a member of LIT-SIS in AALL and maybe we need a special caucus to address this specific technology. Additionally, we can get consortiums of schools together in each state to develop our own LLMs – outside of the subscription-based products that will roll out for Lexis and Westlaw. Anything we build ourselves will have the needs of our community at the forefront. We can build in all of the transparency, privacy, and accuracy that may be lacking in commercial models. Schools can build tools that would not be commercially viable at firms. Firms and courts could build specialized tools to achieve their unique workflows. It opens up many options that are not available if we’re stuck with the one-size-fits-all nature of Lexis and Westlaw subscriptions.
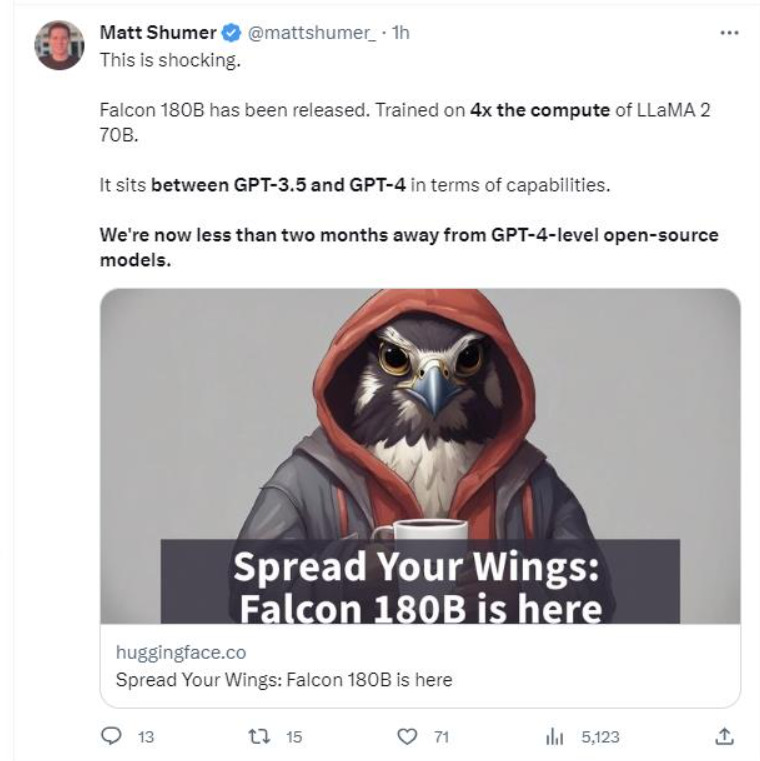
This is an open-source model that is close to competing with GPT4 (ChatGPT’s underlying model). There are many of these and new models show up every day.
There are many options to create, train, and locally run custom LLMs as long as you have the data. As David Shapiro said in the video, “data is the oil of the information age” and law libraries are deep wells of the type of data that could be used to accurately train these services. Additionally, when you are locally hosting an LLM many of the concerns surrounding privacy, permissions, and student data completely evaporate because you are in control of what information is being sent and stored.
To do all of this, we need organization, collaboration, and funding. Individually this could be difficult but if we band together in consortium, we can get a lot done.
Students
Students are an incredible resource in this area. Many of them come to law school with computer science and data science backgrounds and can help with the creation and development of these models. They need mentors and organizers to help focus their efforts, provide resources, and nurture their creativity. In addition, they provide a deep reservoir of diverse voices and experiences that may not occur to people who have spent decades in academia, the public sector, or law firms. We can bring in students to have competitions to create their own LLM apps for law practice and access to justice initiatives. We can fund fellowships to do work at schools, courts, and firms. We can bring them under our wing to usher in the next generation of tech-savvy law librarians. We can leverage the excitement and energy associated with these new tools to attract new talent into our field – I skimmed TikTok and the #ChatGPT hashtag as around 7.7 billion views. To do that, we need to brainstorm together so that we can get these programs in place.
In Sum
As the torchbearers in this promising venture, it’s time for us, the law librarians, to step up and show the world our unmatched prowess in harnessing the potential of LLMs in law, weaving our expert knowledge in information science, law, and emerging technology. Let us band together, utilizing the rich data reserves at our disposal, and carve out a future where legal technology is not just efficient and transparent, but also a collaborative masterpiece fostered by our relentless pursuit of innovation and excellence.